Overview
Karpenter 버전이 어느덧 v0.37이 되었습니다. Karpenter v0.5 이상부터는 정식 버전 (GA, General Availability) 가 되기에 빠른 시일 내 CA 대신 Karpenter 도입을 하는 기업이 더욱 많아질 것이라 예상합니다.
이번 장에서는 Karpenter를 운영 환경에 도입하기 위한 검토 단계로 Karpenter를 테라폼으로 구성하고,
고려사항들을 실습 환경에서 구성하는 내용을 다룰 예정입니다.
Karpenter
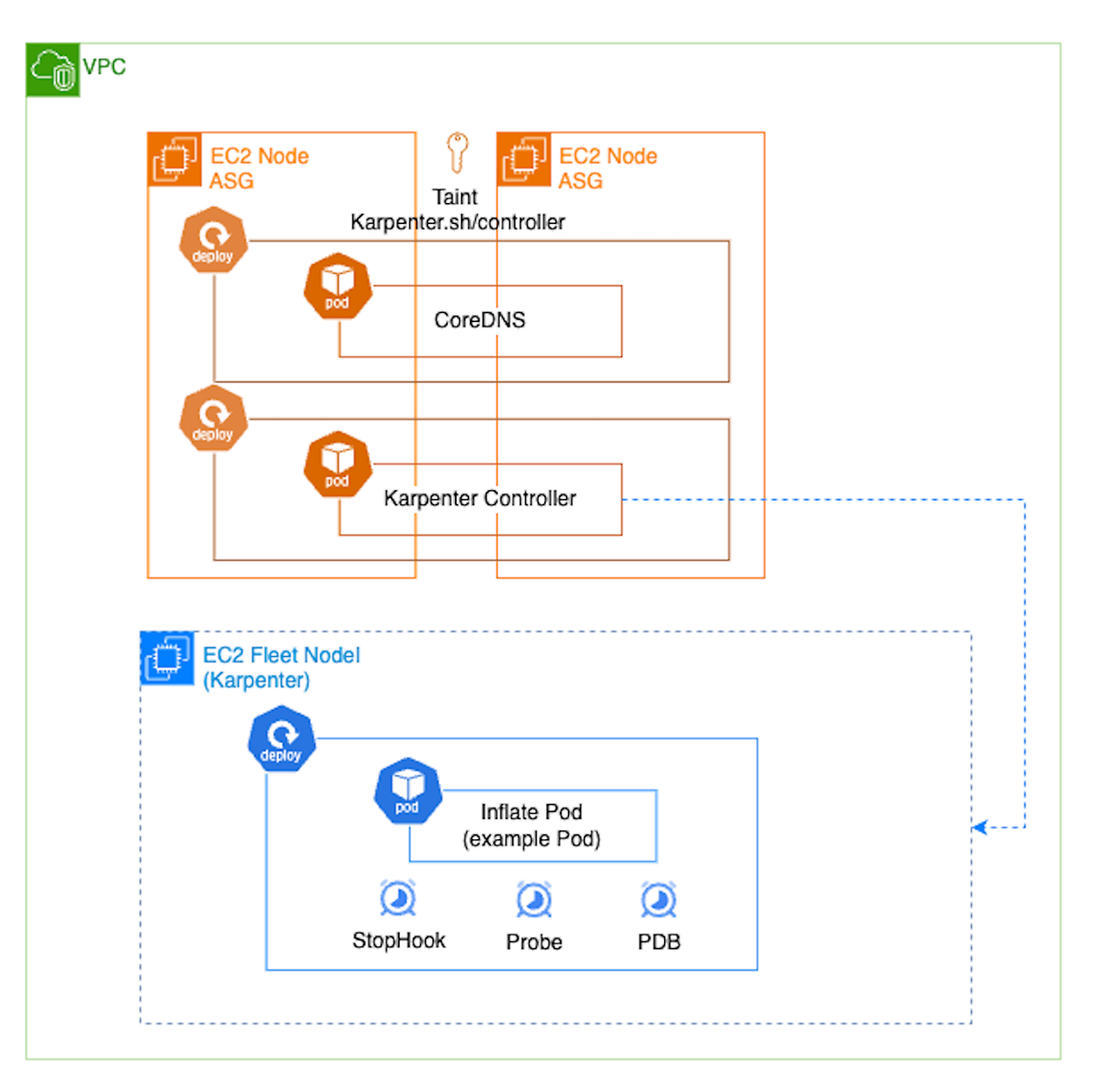
Karpenter EC2 Fleet 기반의 클러스터 오토스케일러입니다. 기존 ASG와 달리 EC2 Fleet으로 노드를 구성하여 빠른 노드 프로비저닝 속도, 다른 인스턴스 타입간의 구성 및 비용최적화로 노드 통합 등의 기능이 지원됩니다.

Karpenter의 자세한 내용은 이전 필자의 블로그에서 카펜터 개념과 운영 고려사항을 다뤘으니 참고 바랍니다.
Kubeflow로 보는 Karpenter
Overview MLOps 플랫폼 Kubeflow의 Karpenter 활용 사례를 참고하여 구성 원리를 알아보겠습니다. Karpenter, 카펜터 활용 사례를 확인하기 전 카펜터를 확인하겠습니다. 카펜터는 EC2 Fleet 기반의 클러스터
hanhorang.tistory.com
Karpenter 고려사항
Overview 카펜터에 대해 검색하면 여러 도입 사례를 확인할 수 있습니다. 도입 사례들을 참고하여 운영 고려사항들을 정리하겠습니다. 노드 자체 제어 기능 비활성화 Karpenter에서는 비용 감소화를
hanhorang.tistory.com
Terraform 으로 Karpenter 을 구성하는 이유?
Karpenter 구성을 위해 Layer 별 다음의 설정이 필요합니다.
- AWS : 카펜터 노드 프로비저닝을 위한 IAM 정책 생성, 노드 프로비저닝 서브넷 태그 설정
- EKS : 클러스터 내 카펜터 권한 설정(aws-auth), 카펜터 컨트롤러 배포 및 CRD(nodeClass & NodePool) 설정
운영 클러스터가 다수이라면 위 단계 구성이 반복적이고 휴먼 에러 가능성이 올라갑니다.
이러한 어려움을 테라폼을 통해 코드로 구성한다면 해결할 수 있을 것이라 예상합니다.
테라폼에서는 카펜터 모듈을 제공하여 IAM 설정 부분을 쉽게 구성할 수 있습니다.

다만, 그외 서브넷 태그와 컨트롤러 배포는 직접 배포가 필요합니다.
특히 컨트롤러 배포에 있어 주의사항이 필요합니다. 주요 파드(CoreDNS, 카펜터 컨트롤러)를 카펜터에 했을 때 문제가 발생하여 기존 노드 그룹에 배포하는 것을 추천하고 있습니다.

카펜터는 버전 업에 따른 노드 교체(Drift) 가능성이 있고 노드 수명 주기(Expiration) 및 통합(Consoildatiomn)을 통해 노드가 언제든지 교체될 수 있습니다. 해당 옵션이 활성화된다고 하면 파드 스케쥴링 설정이 필수이며, 애플리케이션에 따라 노드 교체 옵션을 비활성화하는 사례도 있습니다.
Karpenter 구성 확인
본 장에서는 테라폼 모듈 구성 및 노드 교체를 활성화를 가정하고 파드 스케쥴링도 설정하여 카펜터 기능을 100퍼센트 활용하는 목적으로 구성하겠습니다. 테라폼 구성은 Karpenter on EKS MNG 을 참고하였습니다.
# terraform 1.8.5
git clone https://github.com/aws-ia/terraform-aws-eks-blueprints.git
cd patterns/patterns/karpenter-mng/
tree .
.
├── README.md
├── eks.tf # EKS 및 카펜터 구성
├── example.yaml # 예제 파드
├── karpenter.yaml # CRD
├── main.tf
└── vpc.tf구성을 확인하면 Karpenter 구성을 위한 과정이 포함되어 있습니다.
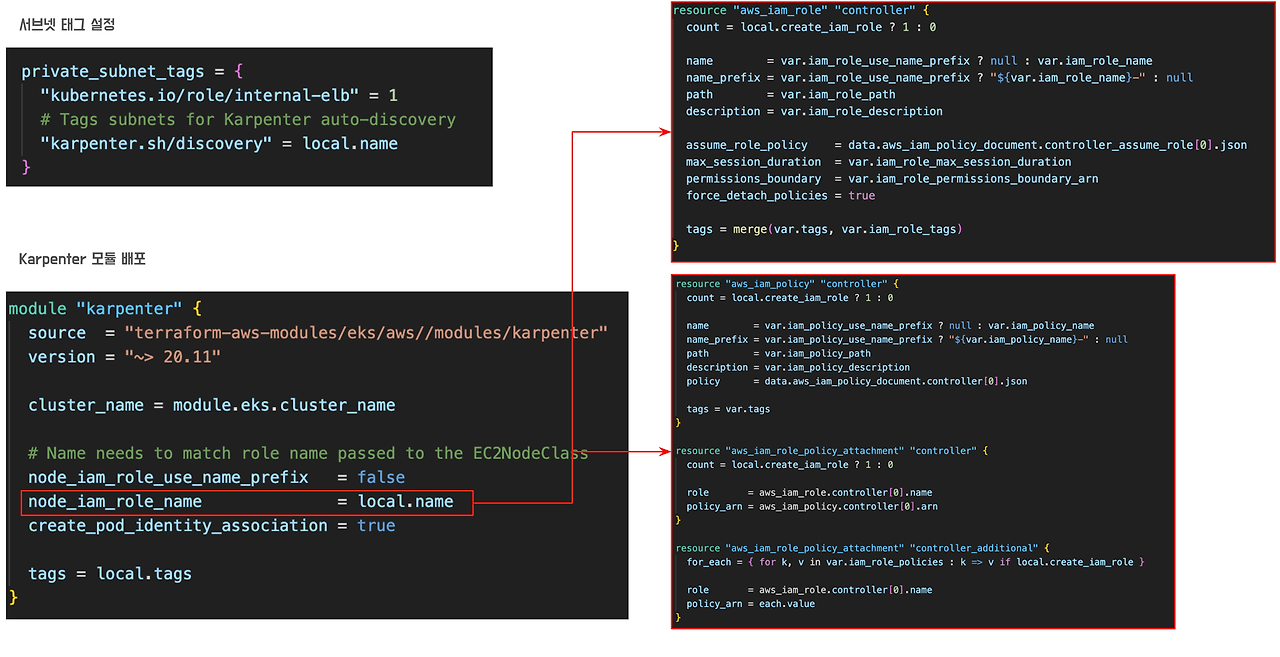
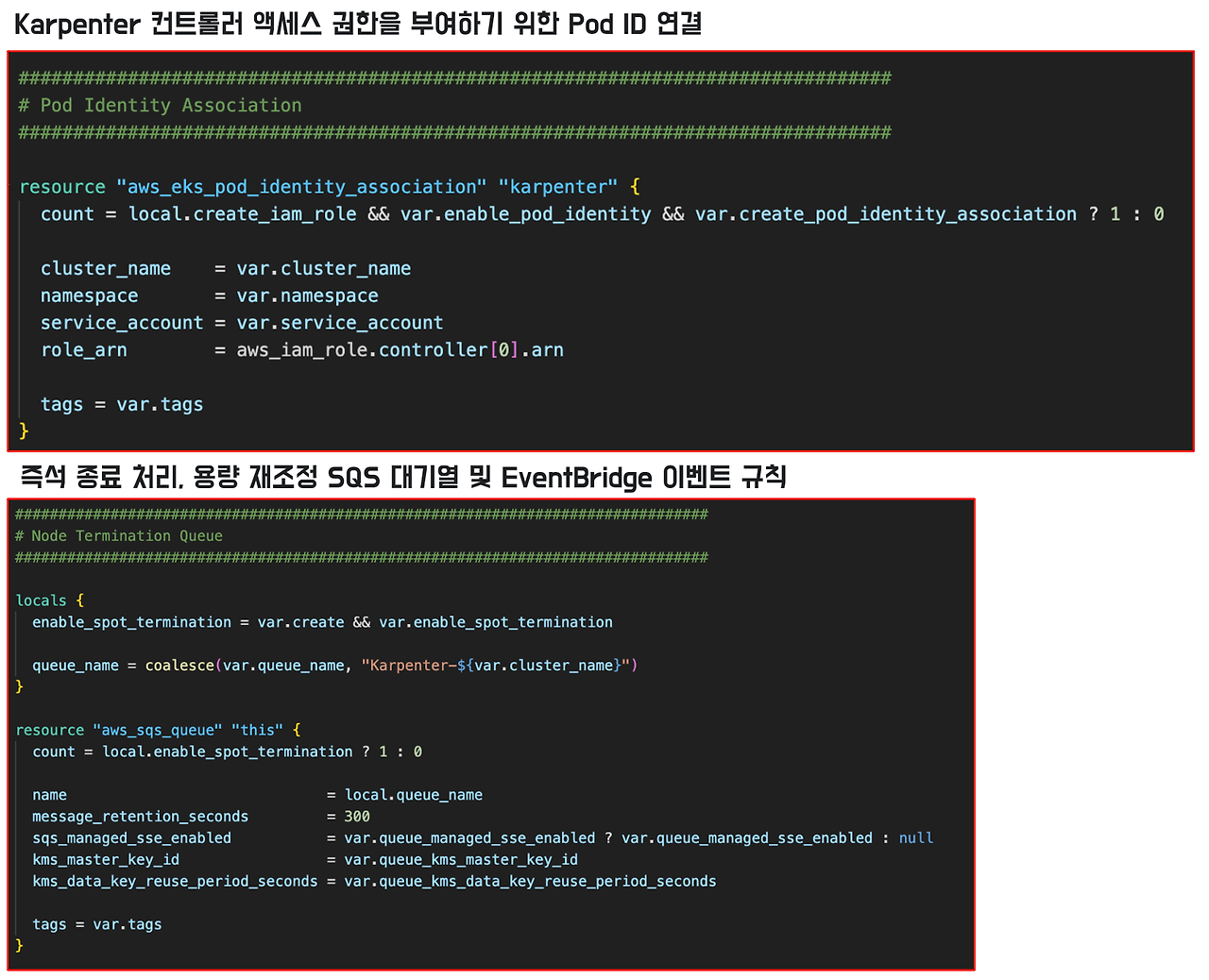
- Pod Identity Association : IAM role을 카펜터 컨트롤러 Pod 에 연결합니다.
- Node Termination Qeue : Spot 인스턴스 termination handling을 하기 위한 설정입니다.
해당 패턴에서는 ASG에 Taint을 설정하여 addon 들을 ASG에 배포하도록 설정되어 있습니다.
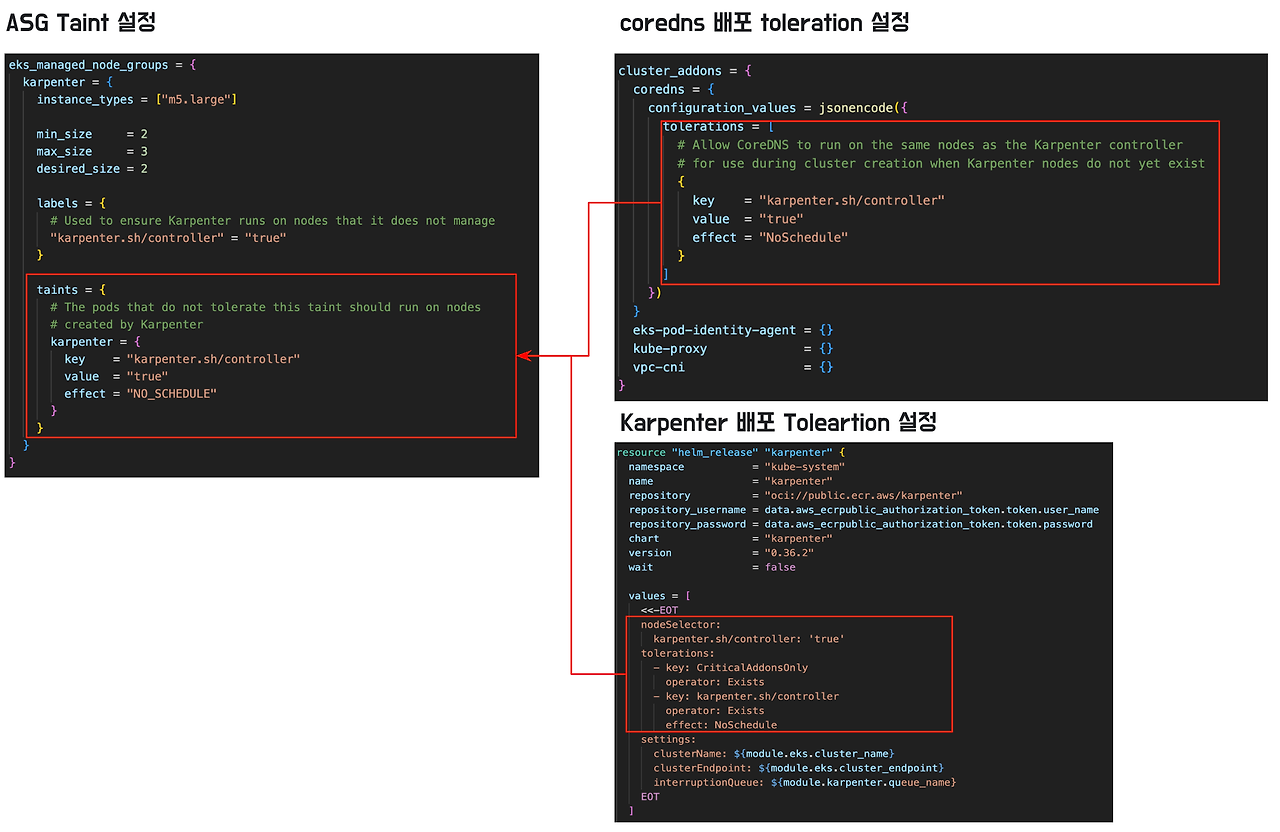
마지막으로 카펜터 노드 그룹에 대한 정의는 karpenter.yaml 에서 확인할 수 있습니다 .
---
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2
role: ex-karpenter-mng
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: ex-karpenter-mng
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: ex-karpenter-mng
tags:
karpenter.sh/discovery: ex-karpenter-mng
---
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
nodeClassRef:
name: default
requirements:
- key: "karpenter.k8s.aws/instance-category"
operator: In
values: ["c", "m", "r"]
- key: "karpenter.k8s.aws/instance-cpu"
operator: In
values: ["4", "8", "16", "32"]
- key: "karpenter.k8s.aws/instance-hypervisor"
operator: In
values: ["nitro"]
- key: "karpenter.k8s.aws/instance-generation"
operator: Gt
values: ["2"]
limits:
cpu: 1000
disruption:
consolidationPolicy: WhenEmpty
consolidateAfter: 30s위 구성 내용을 확인했으면 직접 배포를 진행하겠습니다.
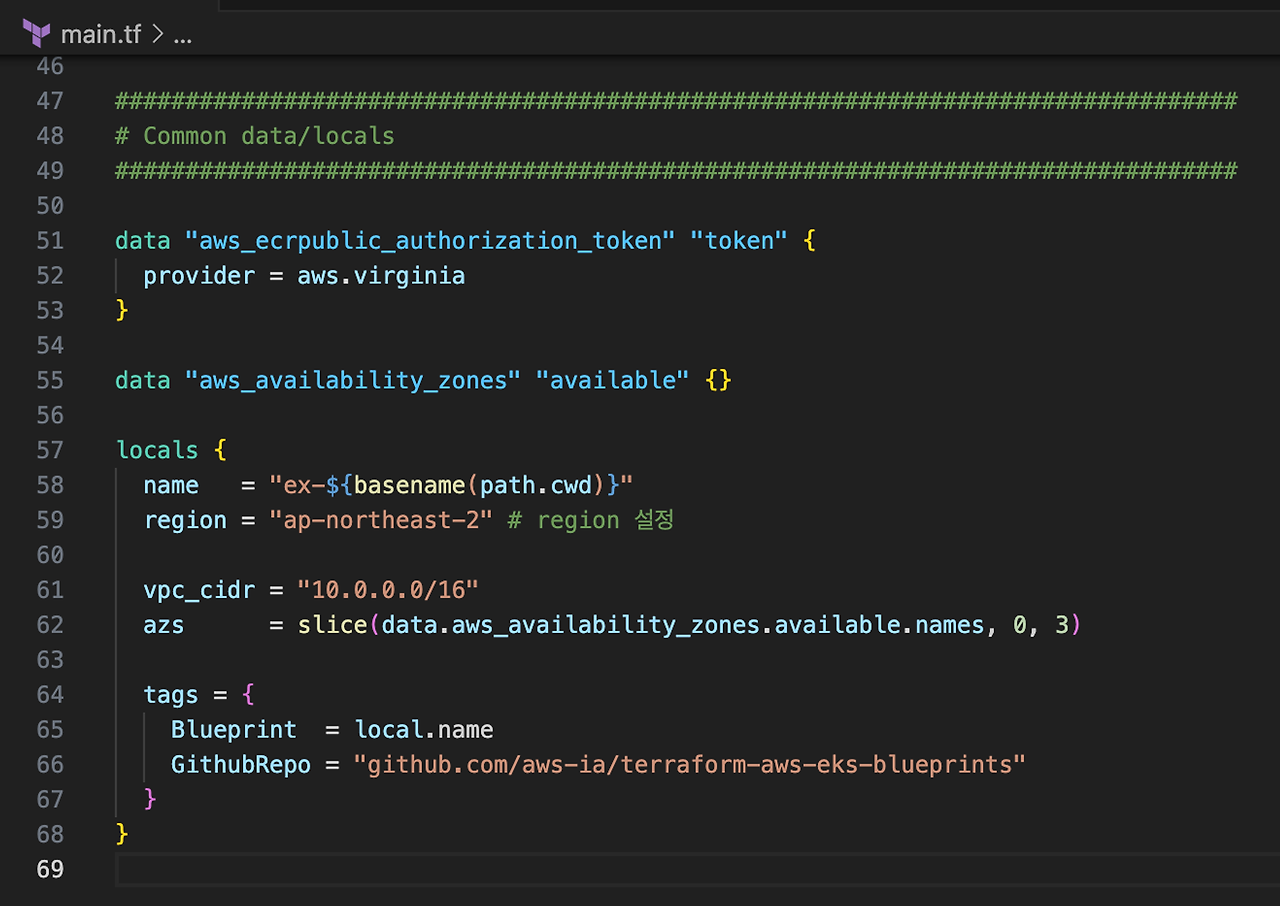
main.tf 에서 다음과 같이 지역 변수를 설정해주세요.
terraform init
terraform plan
terraform apply배포에는 약 15분정도 소요됩니다.
# 클러스터 config 설정
aws eks --region ap-northeast-2 update-kubeconfig --name ex-karpenter-mng
# 노드 및 차트 확인
kubectl get nodes -A
helm list -A 
여기에 노드 모니터링 툴인 kube-ops-view 를 배포하겠습니다.
addon 과 마찬가지로 toleration 설정이 필요합니다.
# kube-ops-view 설치
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm show values geek-cookbook/kube-ops-view > values.yaml
vi values.yaml
..
..
env:
# -- Set the container timezone
TZ: Asia/Seoul
tolerations:
- key: CriticalAddonsOnly
operator: Exists
- key: karpenter.sh/controller
operator: Exists
effect: NoSchedule
..
# 차트 배포
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 -f values.yaml --namespace kube-system
# 포트포워딩
kubectl port-forward -n kube-system svc/kube-ops-view 8080:8080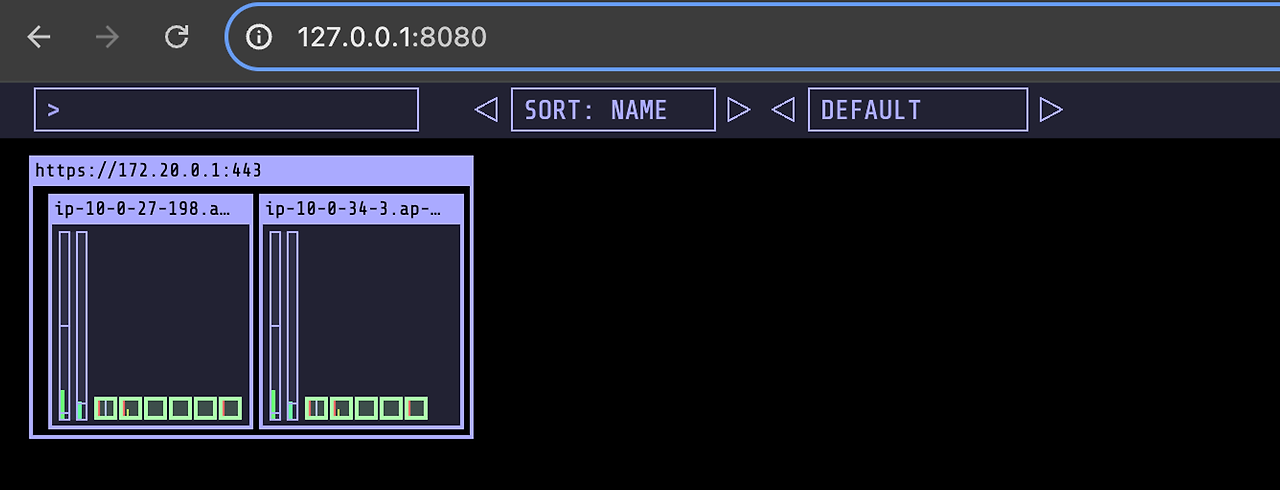
설정이 끝났으면 카펜터 CRD 배포와 예제 파드를 배포하여 Karpenter 구성 동작을 확인하겠습니다.
# 카펜터 CRD 배포
kubectl apply -f karpenter.yaml
# example 파드 배포
kubectl apply -f example.yaml
# 파드 수 설정
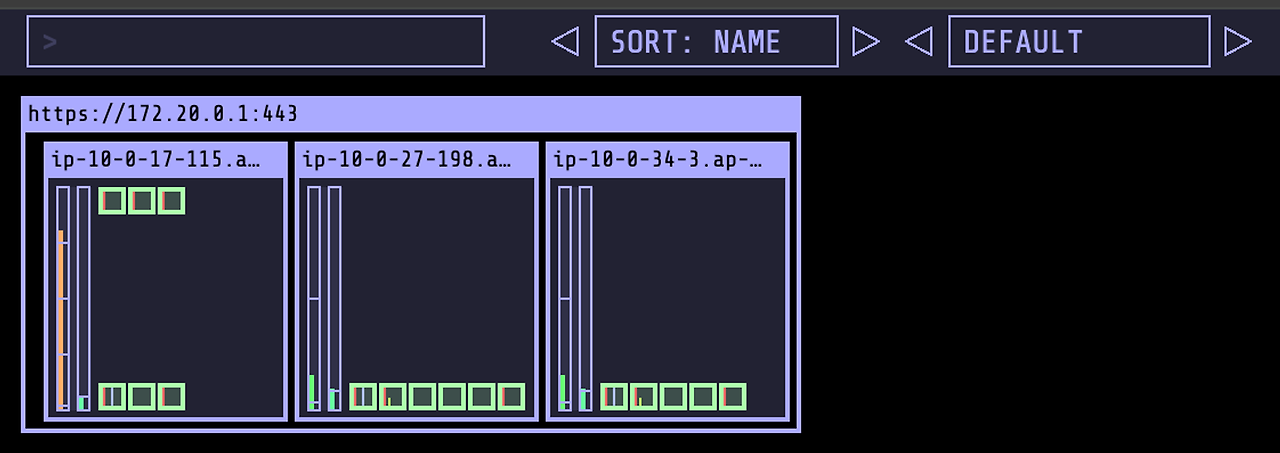
kubectl scale deployment inflate --replicas=3 동작이 굉장히 빠릅니다.
파드 수를 3으로 설정하면 약 30초 이내로 노드 프로비저닝 및 파드 배포가 되는 것을 확인할 수 있습니다.

Karpenter 노드 교체 대비 파드 스케쥴러 설정
위에서 다룬 Addon Taint 설정 이외에도 워크로드 파드에 대해 스케쥴러 설정이 필요합니다.
Karpenter 노드 교체에 따라 연속성이 보장되지 않는다면 서비스 제공에 다운타임이 발생하기 때문입니다.
파드에 추가적으로 적용해야할 사항은 다음과 같습니다.
- Pod Disruption Budget (PDB) 설정 : 파드가 항상 뜰 수 있는 개수를 설정하여 개수 안전성 보장
- Container Probe 설정 : 파드 시작 지점에서 서비스가 정상적으로 구성될 때까지 확인 설정
- Termination 설정 : 파드 종료 시점에서 Grace Shotdown 설정
- 파드 리소스 설정 : Karpenter 도입시 Limit 설정
- 그외(CA, 테라폼 관련)
Pod Disruption Budget (PDB)
PDB 설정하여 특정 파드가 항상 뜰 수 있는 개수를 3개로 설정하여 파드 개수 안정성 보장할 수 있습니다. Pod는 항상 설정된 replica의 수 만큼 유지되지만 시스템 관리로 인해 특정 node를 다운 시켜야 하는 경우, 또는 CA나 카펜터가 node의 수를 줄이는 경우 등과 같은 이유로 pod의 수가 줄어들어야 하는 경우가 있습니다.
이런 경우 PDB를 통해 최소한 운영 가능한 pod의 비율/개수를 정하거나 최대 서비스 가능하지 않은 pod의 비율/개수를 정하여 서비스의 안정성을 보장해야 합니다. Node가 scale down 되어야 하는 상황에서 최소 보장되어야 하는 PDB 설정을 만족하지 못하는 해당 node는 다운되지 않고 기다리다가 만족하는 상황이 되면 그때 다운됩니다.
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: inflate-pdb
spec:
minAvailable: 1
selector:
matchLabels:
app: inflate
Container Probe 설정
Probe 는 애플리케이션의 상태를 모니터링하여 문제가 발생한 컨테이너를 자동으로 재시작하고, 트래픽을 정상적인 컨테이너로만 라우팅하며, 초기화가 완료될 때까지 서비스에 포함되지 않도록 하기 위해 설정합니다. Probe 설정은 크게 3가지로 분류됩니다.
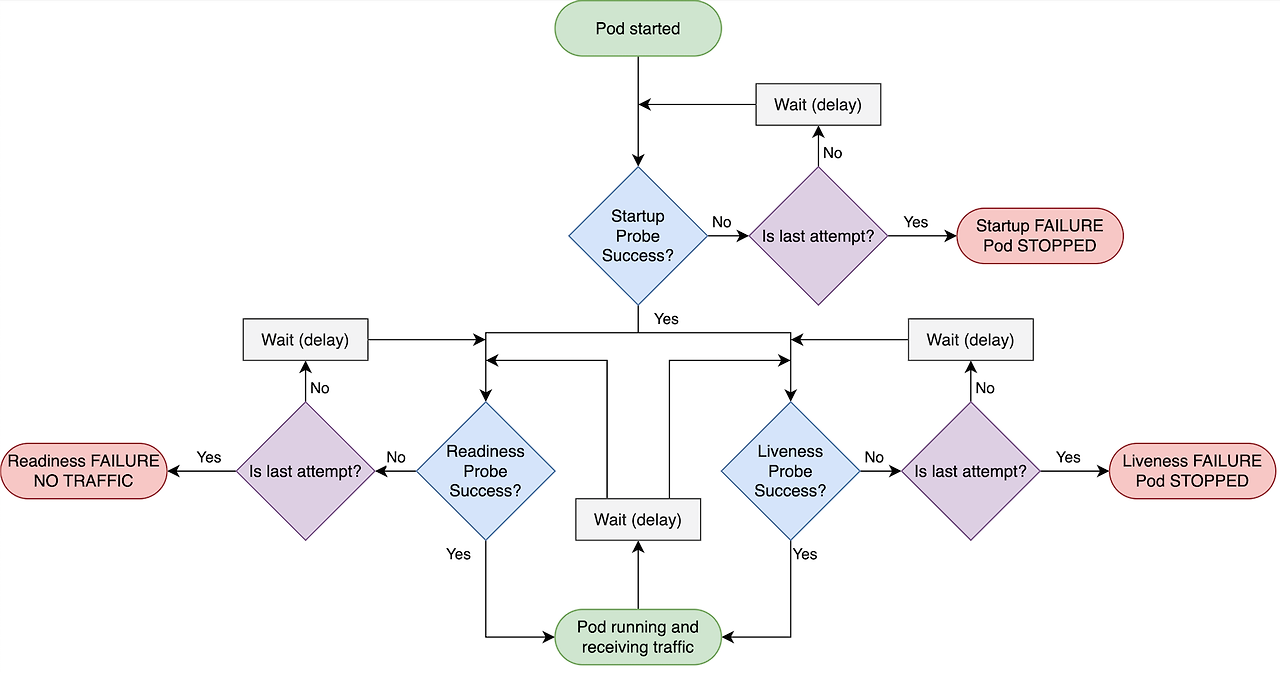
- Startup Probe: Warm-up 시간을 고려하여 초기화 동안 다른 Probe를 실행하지 않음
- Liveness Probe: TCP레벨에서 컨테이너가 정상적으로 작동하고 있는지 확인하는 Probe, 설정 실패시 컨테이너를 재시작합니다.
- Readiness Probe: HTTP 레벨에서 트래픽을 받기 전에 컨테이너가 준비되었는지 확인하는 Probe
다른 기업 사례를 보면 Readiness Probe 는 꼭 설정하며, Liveness Probe는 예외 사항(젠킨스 등 가끔식 죽어서 재시작하는 서버)가 있는 경우 설정하는 편입니다.
단 Probe 초 설정의 경우 애플리케이션에 따라 다르며 Liveness에 따라 재시작이 일어날 수 있으니 반드시 사전 테스트가 필요합니다.
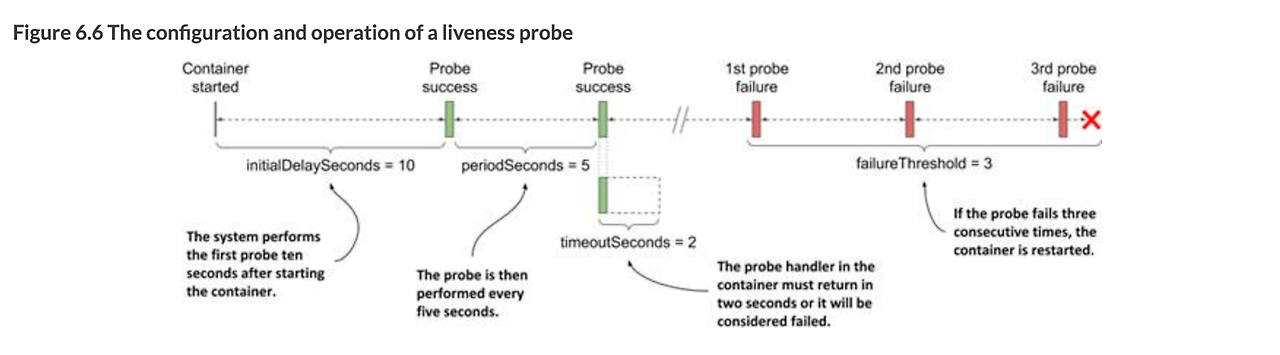
- PHP 처럼 잠깐 부하가 있지만, 조금만 견디면 바로 복구되는 서비스라면 failuerThreshold를 올리는 것도 방법
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 0
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 0
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
resources:
requests:
cpu: 1
readinessProbe: # probe 설정
httpGet:
path: /
port: 80
initialDelaySeconds: 5
periodSeconds: 10
PreStop, PostStop 을 통한 Grace Shotdown
기존 파드가 트래픽 처리 중이나 응답을 주기 전에 파드가 종료되는 경우 장애 발생(5XX) 합니다.
이를 방지하기 위해 Stop Hook 설정이 필요합니다.
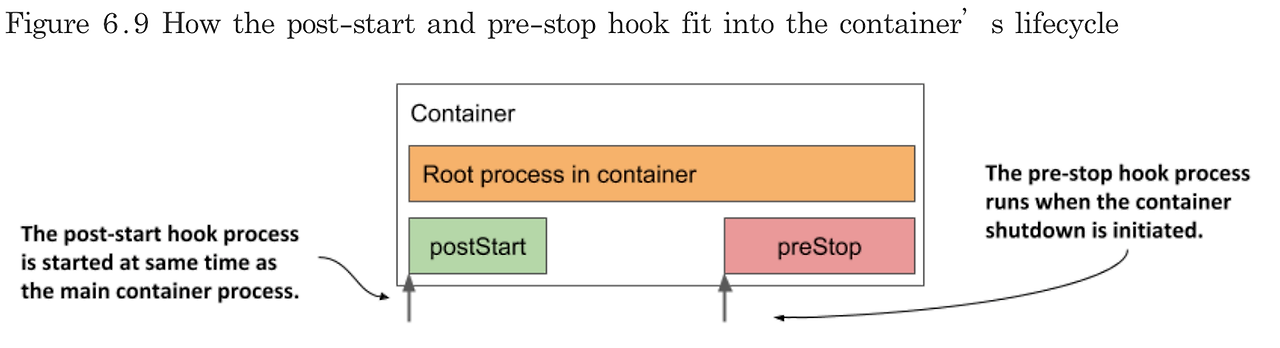
- PreStop: 컨테이너가 종료되기 전에 실행되는 명령 또는 스크립트로, 종료 전 정리 작업을 수행합니다.
- PostStop: 컨테이너가 종료된 후 실행되는 명령 또는 스크립트로, 종료 후 후속 작업을 수행합니다.
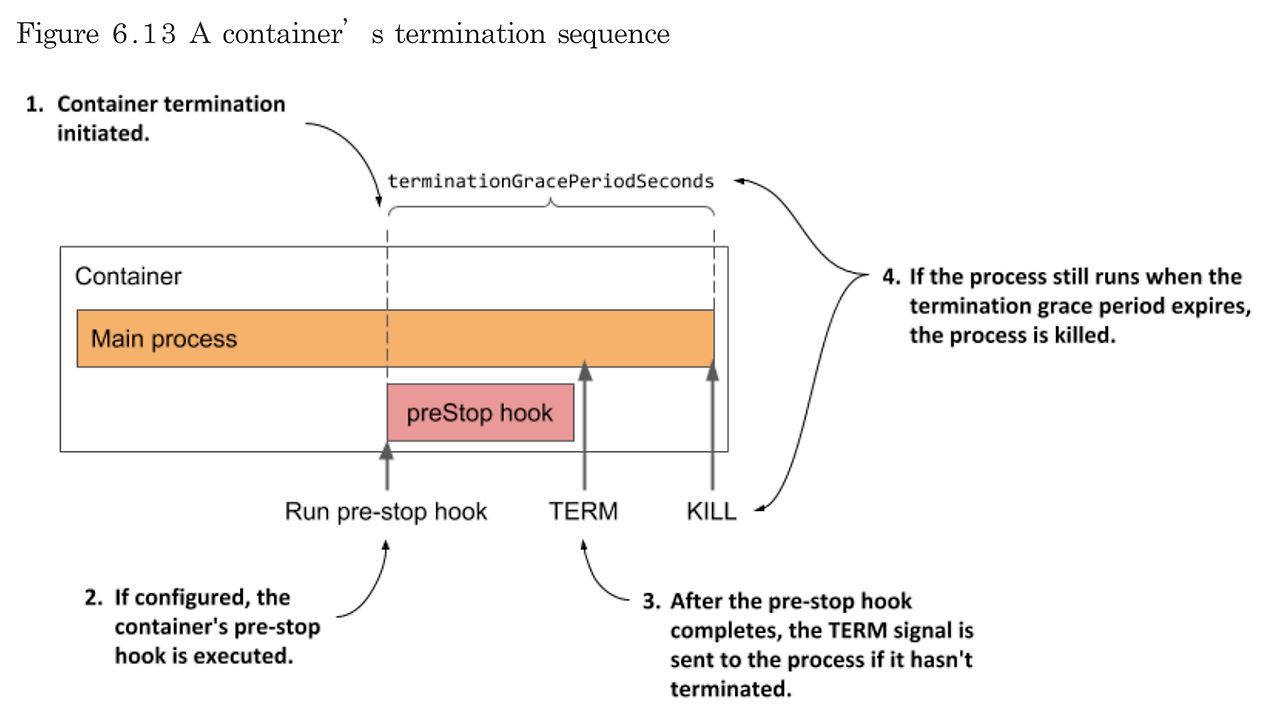
Hook 동작은 쿠버네티스 API 서버가 Pod 삭제 요청을 받아 상태를 Terminating으로 변경하고, Kubelet은 이를 감지하여 preStop 훅을 실행한 후 SIGTERM 시그널을 전송하여 컨테이너를 정상 종료시킵니다. 종료 기간 내에 종료되지 않으면 SIGKILL 시그널로 강제 종료하고, 모든 컨테이너가 종료되면 Pod 종료 상태를 API 서버에 보고합니다.
terminationGracePeriodSeconds 값을 애플리케이션 종료시간보다 길게 설정하면 서비스영향도 없이 파드를 안전하게 종료할 수 있습니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 0
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 30 # 종료 시간 설정
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
resources:
requests:
cpu: 1
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 5
periodSeconds: 10
lifecycle: # Hook 설정
preStop:
exec:
command: ["/bin/sh", "-c", "echo 'Pod is terminating'"] # 로그 이벤트 설정
- Hook 핸들러 로그는 파드 이벤트에 노출되지 않습니다. 결과 이벤트를 출력하기 위해서는 command 설정해야 합니다.
파드 리소스 limit 설정
기술 테크 블로그나 활용 사례에서 파드 limit 설정을 지정하지 않은 패턴이 자주 보입니다. 다만, 카펜터 도입과 통합 기능(consolidation) 을 사용한다면 파드에 메모리 수치가 폭발적으로 늘어나는 워크로드가 있다면 반드시 Limit를 request와 동일하게 설정해야 합니다.

그 외 (테라폼, CA )
위에서는 쿠버네티스 파드 스케쥴링에 대해 구성을 다뤘습니다.
여기서는 그 외 ASG에서 Karpenter로 넘어가는 경우 추가 사항을 공유합니다.
테라폼 EKS node desired 설정
테라폼으로 배포된 EKS에 CA나 카펜터로 노드 오토스케일링 되면 desired 사이즈가 변하게 됩니다. 변하게 된 이후 테라폼으로 다시 프로비저닝 시 노드 수가 처음 설정대로 돌아가 예상치 못한 에러가 발생할 수 있습니다.
테라폼으로 구성시 노드 설정 부분은 ignore_changes를 통해 사이즈 변경을 예방하는 것을 추천드립니다.
CA → Karpenter
본 장에서는 CA가 없었지만 운영기에서 Karpenter를 도입했다면 CA를 비활성화해야 합니다.
kubectl scale deploy/cluster-autoscaler -n kube-system --replicas=0기타 다른 BP 사례들은 카펜터 공식문서를 참고해주세요
Karpenter - EKS Best Practices Guides
Karpenter Best Practices Karpenter Karpenter is an open-source project that provides node lifecycle management for Kubernetes clusters. It automates provisioning and deprovisioning of nodes based on the scheduling needs of pods, allowing efficient scaling
aws.github.io
리소스 정리
위 Karpenter 를 위해 구성한 인프라는 다음과 같이 삭제해주세요.
# 리소스 정리
kubectl delete -f example.yaml
kubectl delete -f karpenter.yaml
# 인프라 정리
terraform destroy
'Cloud Tech' 카테고리의 다른 글
| Kafka on EKS (0) | 2024.07.27 |
|---|---|
| EKS에서 Atlantis 구성하기 (0) | 2024.07.14 |
| 테라폼 모듈을 활용한 Cloudwatch 알람 자동화(심화) (0) | 2024.06.29 |
| 테라폼 모듈을 활용한 CloudWatch Alarm 자동화 (0) | 2024.06.22 |
| Terraform 내부 로직 이해 (0) | 2024.06.15 |