Overview
Amazon EKS에 Apache Kafka를 배포하고, 여러 운영 시나리오를 실습하겠습니다.
해당 글은 AWS 공식문서를 참고하였습니다.
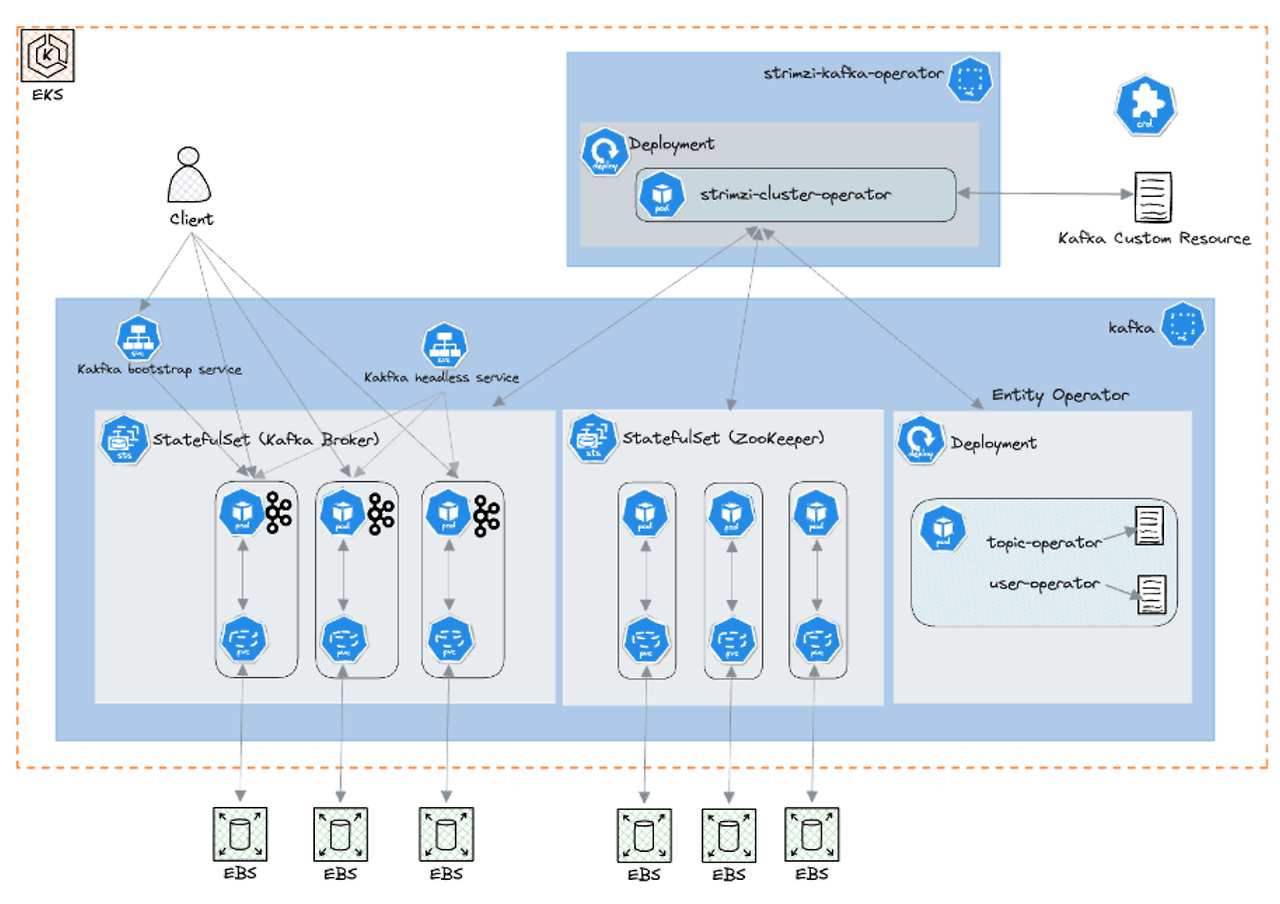
Kafka on EKS
Apache Kafka는 이벤트 기반 아키텍처를 가진 분산 스트리밍 플랫폼입니다. Kafka는 수평 확장 가능하고, 내결함성이 있으며, 성능이 뛰어납니다.
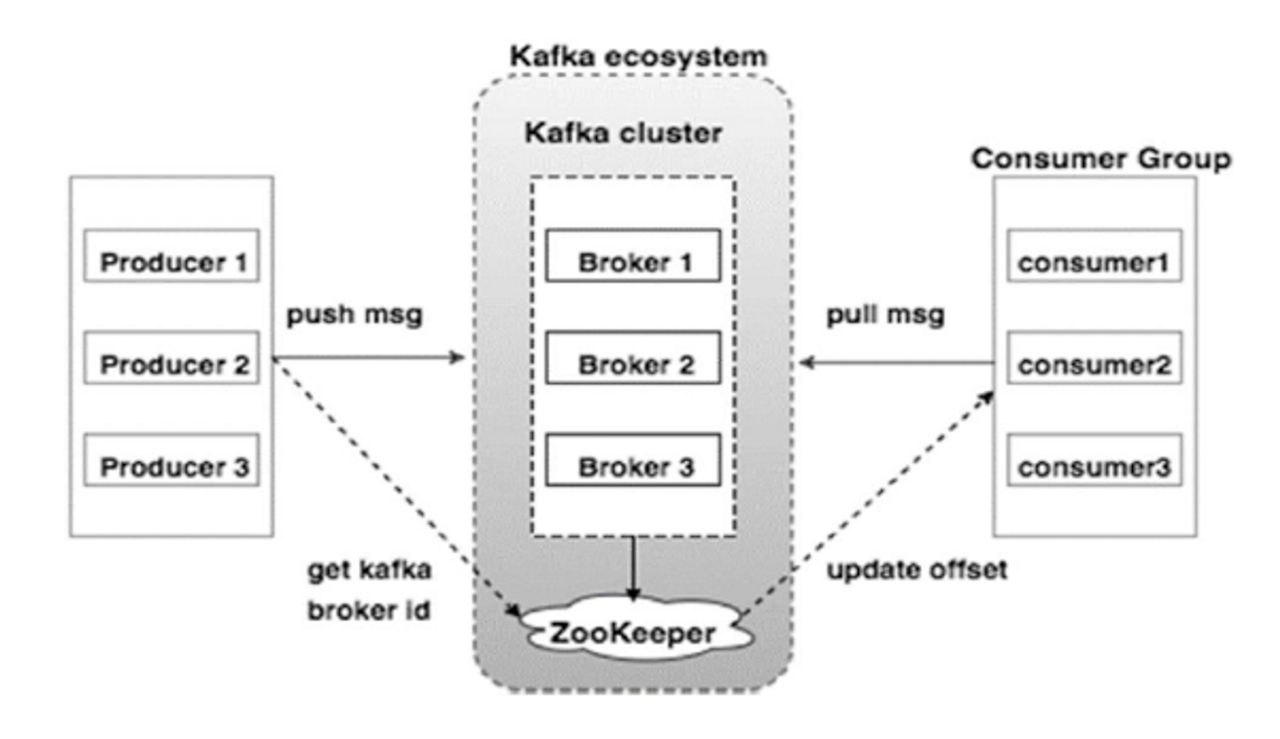
- 내결함성 : 메세지를 생산하는 Producer와 메세지를 소비하는 Consumer를 분리하여 서로의 영향도 없이 메세지를 비동기적으로 통신할 수 있습니다.
- 수평 확장 : Kafka는 Broker를 통해 메세지를 처리합니다. 메세지 양에 따라 Broker를 확장하여 많은 메세지를 처리할 수 있습니다.
다만, Kafka 클러스터를 수동으로 관리하고 확장이 어렵고, 시간이 많이 걸릴 수 있습니다. 여기서 쿠버네티스는 Kafka를 실행하기 위한 강력한 플랫폼을 제공하여 롤릴 업데이트, 서비스 검색, 로드밸런싱 그리고 자동 복구 기능을 제공하여 고가용성을 유지시킬 수 있습니다.
쿠버네티스에서는 Kafka 클러스터를 배포하기 위한 Strimzi Operator가 있으며, 복잡한 Kafka의 배포와 관리를 간소화할 수 있습니다. 또한, EKS에서는 Data on EKS(DOEKS)라는 Terraform기반의 청사진을 통해 인프라와 Kafka를 한번에 배포하여 관리할 수 있습니다. DoEKS에 대해 다양한 참고 문서가 많습니다. 한 번씩 참고하시는 것을 추천드립니다.
Kafka on EKS | Data on EKS
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
awslabs.github.io
data-on-eks/streaming/kafka at main · awslabs/data-on-eks
DoEKS is a tool to build, deploy and scale Data & ML Platforms on Amazon EKS - awslabs/data-on-eks
github.com
Kafka on EKS 구성
DoEKS를 기반으로 EKS를 구성하고 Kafka를 배포하겠습니다. 구성은 테라폼을 통해 진행합니다.
테라폼 프로비저닝 전 몇가지 코드 수정이 필요합니다.
24년 7월 27일 기준 EKS 1.27 표준 지원이 만료되었습니다.
비용 감소를 위해 EKS 버전 업데이트 및 노드 그룹을 최소화하고, EBS 볼륨을 1000에서 200으로 줄여주세요.
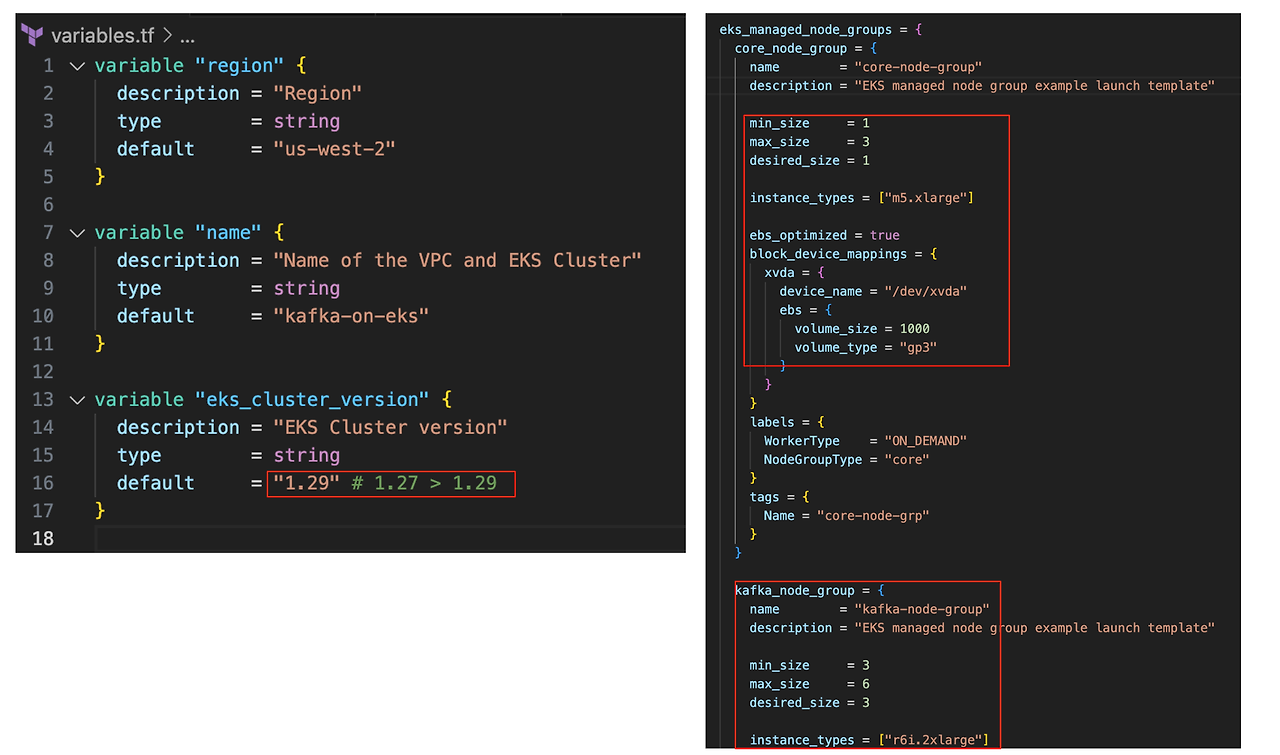
필자는 배포 후 확인하여 수정하지 못했습니다.
git clone https://github.com/awslabs/data-on-eks.git
cd data-on-eks/streaming/kafka
export AWS_REGION="ap-northeast-2" # Select your own region
terraform init
terraform apply -var region=$AWS_REGION --auto-approve 테라폼으로 구성시 coredns, aws-ebs-csi-driver 에서 구성 시간이 오래걸릴 수 있습니다.
아래 메세지가 계속된다면 취소 후 다시 구성해주세요.

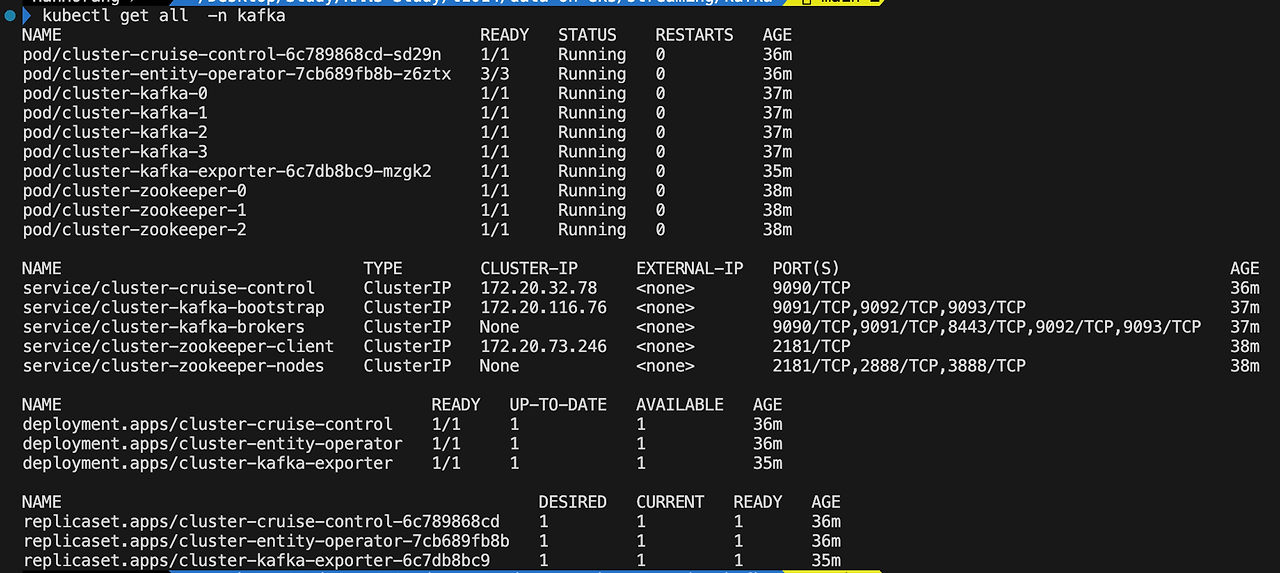
구성이 완료되면 다음과 같이 구성을 확인할 수 있습니다.
aws eks --region $AWS_REGION update-kubeconfig --name kafka-on-eksKafka 클러스터는 고가용성을 위해 다중 가용성 영역으로 배포합니다. 예제에서는 고가용성 달성을 위해 AZ별 최소 1개의 노드를 배포하였습니다.


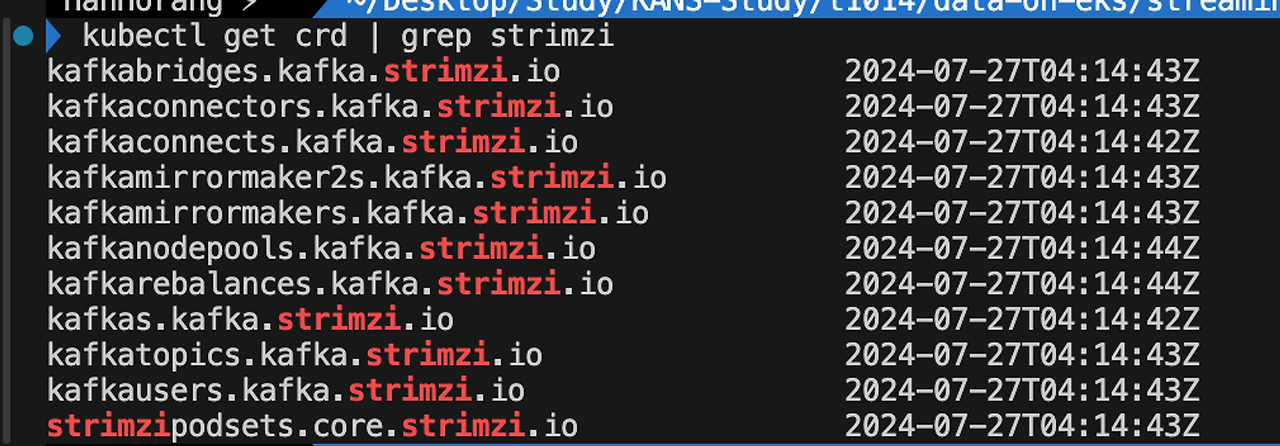
strimzi-kafka-operator가 배포한 구성을 확인할 수 있습니다. Kafka Broker와 Zookepper 포드를 확인할 수 있습니다.
strimzi는 Kafka 객체를 쿠버네티스 CRD를 통해 관리합니다. Kafka 관리에 필요한 것들을 쿠버네티스 객체와 같이 yaml로 구성할 수 있습니다.

Kafka 토픽 생성 및 샘플 테스트
Topic은 Kafka에서 메세지를 구성하는 데 사용되는 범주입니다. 각 토픽은 Kafka 클러스터 전체에서 고유한 이름을 갖습니다. 메세지는 특정 토픽으로 전송되고, 특정 토픽에서 읽힙니다. 각 토픽은 브로커 간에 분할되고 복제됩니다.
DoEKS에서 제공하는 예제를 통해 토픽을 생성하고 파티션 구성을 확인하겠습니다.
# data-on-eks/streaming/kafka
kubectl apply -f examples/kafka-topics.yaml
# kafka-topics.yaml
cat kafka-topics.yaml
----
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: my-topic
namespace: kafka
labels:
strimzi.io/cluster: cluster
spec:
replicas: 3
partitions: 12
---
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: my-topic-reversed
namespace: kafka
labels:
strimzi.io/cluster: cluster
spec:
replicas: 3
partitions: 12- my-topic, my-topic-reversed 토픽을 생성하고 replicas는 3, partitions는 12로 생성합니다.

토픽 파티션이 브로커에 복제되었는 지 확인하겠습니다.
# Kafka CLI 생성
kubectl -n kafka run --restart=Never --image=quay.io/strimzi/kafka:0.38.0-kafka-3.6.0 kafka-cli -- /bin/sh -c "exec tail -f /dev/null"
# 카프카 토픽 확인
kubectl -n kafka exec -it kafka-cli -- bin/kafka-topics.sh \
--describe \
--topic my-topic \
--bootstrap-server cluster-kafka-bootstrap:9092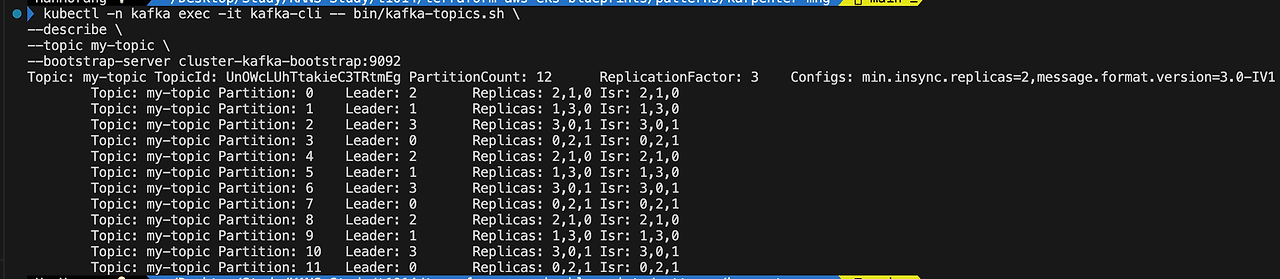
- Leader: [Leader Broker ID]: 각 파티션의 리더 브로커를 나타냅니다. 리더는 클라이언트로부터 데이터를 수신하고 다른 브로커에게 데이터를 전파합니다. 예를 들어, Partition 0의 리더는 브로커 2입니다.
- Replicas: [Replica Broker IDs]: 파티션의 모든 복제본이 저장된 브로커들의 ID입니다. 복제본은 파티션 데이터를 다른 브로커에 복사하여 데이터의 가용성과 내구성을 높입니다. 예를 들어, Partition 0의 복제본은 브로커 2, 1, 0에 저장되어 있습니다.
- Isr: [ISR Broker IDs]: In-Sync Replica의 리스트입니다. ISR은 현재 리더와 동기화되어 최신 데이터를 가지고 있는 복제본을 나타냅니다. 리더와의 동기화가 유지되는 복제본은 ISR에 포함되며, 그렇지 않은 경우 ISR에서 제외됩니다. 이 리스트에 포함된 복제본들은 데이터 손실 없이 최신 상태를 유지하고 있음을 의미합니다. 예를 들어, Partition 0의 ISR은 브로커 2, 1, 0입니다.
- 독립성 보장 : 구성 클러스터에는 최소 3개의 브로커가 있고, 각각 다른 AZ에 있으며, 토픽은 복제 계수가 3이고 최소 In-Sync Replica(ISR)가 2입니다. 이를 통해 단일 브로커가 다운되어도 acks=all인 프로듀서에 영향을 미치지 않습니다.
파티션을 확인하면 리더가 원형으로 구성되어 있음을 확인할 수 있습니다.
Partition 0 → Partition 2 → Partition 3 → Partition 0
- Leader: 2 (브로커 2가 리더) → Leader: 3 (브로커 0가 리더)
- Replicas: 2, 1, 0 (브로커 2, 1, 0에 파티션 복제본이 있음)
- Isr: 2, 1, 0 (브로커 2, 1, 0이 리더와 동기화된 상태)
만약 ISR의 수가 min.insync.replicas 설정값보다 작아지면, 해당 파티션에 대한 쓰기 작업은 실패하게 됩니다. 일관성과 동기화를 유지할 수 없기 때문입니다. 위 ISR에는 3개의 복제본이 있어, 쓰기 작업이 성공적으로 수행됨을 확인할 수 있습니다.
이어서 구성한 토픽에 메세지를 생성하여 읽기 및 쓰기를 확인하겠습니다.
kubectl apply -f examples/kafka-producers-consumers.yaml
# kafka 메세지 생산자, 스트림(중간), 소비자 확인
kubectl -n kafka get pod -l 'app in (java-kafka-producer,java-kafka-streams,java-kafka-consumer)'
# 로그 확인
kubectl -n kafka logs \
$(kubectl -n kafka get pod -l app=java-kafka-producer -o jsonpath='{.items[*].metadata.name}')
kubectl -n kafka logs \
$(kubectl -n kafka get pod -l app=java-kafka-streams -o jsonpath='{.items[*].metadata.name}')
kubectl -n kafka logs \
$(kubectl -n kafka get pod -l app=java-kafka-consumer -o jsonpath='{.items[*].metadata.name}')
Kafka 클러스터 확장
Kafka 브로커 확장은 다음의 이점이 있어 고려할 수 있습니다.
- 장애 영향 최소화 : 확장 노드에 데이터 복제와 분산으로 장애의 영향을 줄이고 시스템의 복원력 보장
- 성능 개선: 여러 노드에 데이터 처리를 균형 있게 조정할 수 있어 대기 시간을 줄일 수 있습니다.
여담이지만, 브로커수를 관리하는 Zookeeper의 복제본 수는 클러스터 크기에 따라 최소 3개, 5개, 7개 설정을 권고하고 있습니다. 이는 쿠버네티스 컨트롤 노드와 같이 장애가 발생한 경우 리더 선거를 수행하기 위한 다수결이 필요하기 때문입니다.
쿠버네티스에서는 브로커를 CRD로 관리할 수 있어 브로커 수를 쉽게 조절할 수 있습니다. 필자는 4에서 5로 설정하겠습니다.
kubectl describe kafka -n kafka
---
...
..
Kafka:
Config: # 설정 확인
default.replication.factor: 3
inter.broker.protocol.version: 3.6
min.insync.replicas: 2
offsets.topic.replication.factor: 3
transaction.state.log.min.isr: 2
transaction.state.log.replication.factor: 3
..
..
Replicas: 5 # 브로커 수 조정 가능, 5로 변경 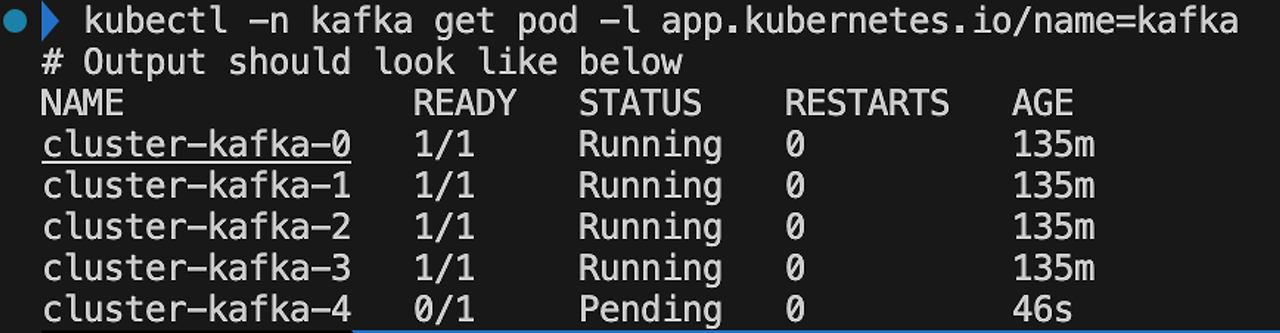
다만, 카프카 토픽의 기존 파티션의 여전히 초기 브로커에 쌓여 있으므로 불균형이 있기에 클러스터 밸런싱이 필요합니다.
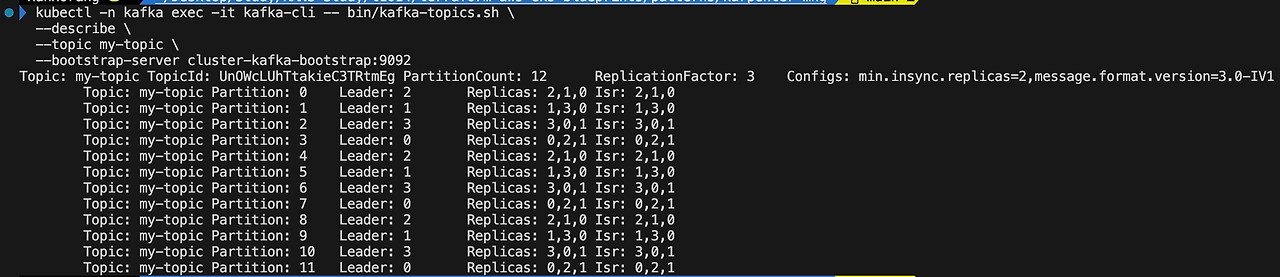
- Replicas(브로커)에 4가 없음
클러스터 밸런싱은 Kafka Cruise Control 를 통해 조정할 수 있습니다.
Kafka Cruise Control는 Kafka 클러스터의 동적 워크로드 재조정 및 자체 복구를 완전히 자동화하도록 설계된 도구입니다. Cruise Control은 전체 클러스터를 재밸런싱하는 것 외에도 브로커를 추가 및 제거하거나 토픽 복제본 값을 변경할 때 이 밸런싱을 자동으로 수행할 수 있는 기능도 갖추고 있습니다.
클러스터에는 이미 Cruise Control가 실행 중으로 최적화 제안을 생성하여 파티션 재조정을 진행하겠습니다.
kubectl -n kafka get pod -l app.kubernetes.io/name=cruise-control
---
NAME READY STATUS RESTARTS AGE
cluster-cruise-control-69675d4c8b-5bf8q 1/1 Running 0 2m1s
# data-on-eks/streaming/kafka
kubectl apply -f kafka-manifests/kafka-rebalance.yamlKafkaRebalance 리소스를 생성하게 되면 최적화 제안을 확인할 수 있습니다.
kubectl -n kafka describe KafkaRebalance my-rebalance
----
Name: my-rebalance
Namespace: kafka
Labels: strimzi.io/cluster=cluster
Annotations: <none>
API Version: kafka.strimzi.io/v1beta2
Kind: KafkaRebalance
Metadata:
Creation Timestamp: 2024-07-27T06:37:43Z
Generation: 1
Resource Version: 47014
UID: 45bde083-320a-4ffc-aab1-166f2c8116cd
Spec:
Goals:
RackAwareGoal
ReplicaCapacityGoal
DiskCapacityGoal
NetworkInboundCapacityGoal
NetworkOutboundCapacityGoal
CpuCapacityGoal
ReplicaDistributionGoal
DiskUsageDistributionGoal
NetworkInboundUsageDistributionGoal
NetworkOutboundUsageDistributionGoal
TopicReplicaDistributionGoal
LeaderReplicaDistributionGoal
LeaderBytesInDistributionGoal
Status:
Conditions:
Last Transition Time: 2024-07-27T06:37:44.046289902Z
Status: True
Type: ProposalReady
Observed Generation: 1
Optimization Result:
After Before Load Config Map: my-rebalance
Data To Move MB: 0
Excluded Brokers For Leadership:
Excluded Brokers For Replica Move:
Excluded Topics:
Intra Broker Data To Move MB: 0
Monitored Partitions Percentage: 100
Num Intra Broker Replica Movements: 0
Num Leader Movements: 36 # 리더 이동의 수
Num Replica Movements: 77 # 복제 이동의 수
On Demand Balancedness Score After: 79.69565546909718 # 균형 후 점수
On Demand Balancedness Score Before: 74.16652216699164 # 균형 전 점수
Provision Recommendation:
Provision Status: RIGHT_SIZED
Recent Windows: 1
Session Id: 9cb90c9c-76c9-451e-86ce-a1c6e0fbcfa0
Events: <none>- 제안에 의해 점수가 74에서 79로 변함으로 최적화 제안을 진행하겠습니다. 다만, 리더 및 Replicas 조정에 의한 리밸런싱 과정에서 순단 및 성능 저하가 발생할 수 있습니다.
KafkaRebalance 리소스에 주석을 달아 해당 제안을 기반으로 재조정을 실행할 수 있습니다.
# 주석 추가
kubectl -n kafka annotate kafkarebalance my-rebalance strimzi.io/rebalance=approve
# 리배런싱 확인
kubectl -n kafka describe KafkaRebalance my-rebalance
----
..
..
Status:
Conditions:
Last Transition Time: 2024-07-27T06:45:08.228623689Z
Status: True
Type: Rebalancing # 리밸런싱 중
..- Status 가 Ready 되어야 합니다.
리밸런싱 완료되면 Replicar가 4로 지정되어 있음을 확인할 수 있습니다.
kubectl -n kafka exec -it kafka-cli -- bin/kafka-topics.sh \
--describe \
--topic my-topic \
--bootstrap-server cluster-kafka-bootstrap:9092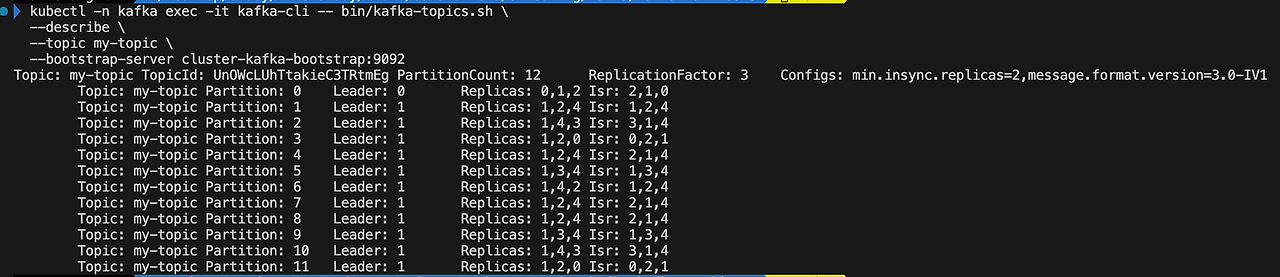
Kafka 클러스터 벤치마킹
Kafka에는 부하테스트를 위한 스크립트가 제공됩니다.
스크립트는 프로듀스 / 소비자에 대해 각각 성능을 테스트할 수 있게 구성되어 있습니다.
부하테스트 스크립트는 다음을 통해 확인할 수 있습니다.
kubectl exec cluster-kafka-0 -it /bin/bash -n kafka
---
[kafka@cluster-kafka-0 bin]$ cd bin
[kafka@cluster-kafka-0 bin]$ ls
connect-distributed.sh kafka-console-producer.sh kafka-jmx.sh kafka-run-class.sh trogdor.sh
connect-mirror-maker.sh kafka-consumer-groups.sh kafka-leader-election.sh kafka-server-start.sh windows
connect-plugin-path.sh kafka-consumer-perf-test.sh kafka-log-dirs.sh kafka-server-stop.sh zookeeper-security-migration.sh
connect-standalone.sh kafka-delegation-tokens.sh kafka-metadata-quorum.sh kafka-storage.sh zookeeper-server-start.sh
kafka-acls.sh kafka-delete-records.sh kafka-metadata-shell.sh kafka-streams-application-reset.sh zookeeper-server-stop.sh
kafka-broker-api-versions.sh kafka-dump-log.sh kafka-mirror-maker.sh kafka-topics.sh zookeeper-shell.sh
kafka-cluster.sh kafka-e2e-latency.sh kafka-producer-perf-test.sh kafka-transactions.sh
kafka-configs.sh kafka-features.sh kafka-reassign-partitions.sh kafka-verifiable-consumer.sh
kafka-console-consumer.sh kafka-get-offsets.sh kafka-replica-verification.sh kafka-verifiable-producer.sh
[kafka@cluster-kafka-0 bin]$ cat kafka-producer-perf-test.sh
#!/bin/bash
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx512M"
fi
exec $(dirname $0)/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance "$@"위 스크립트를 통해 성능 테스트를 진행하겠습니다. 먼저 테스트를 위한 토픽을 생성하겠습니다.
# 벤치마킹을 위한 토픽 생성
kubectl exec -it kafka-cli -n kafka -- bin/kafka-topics.sh \
--create \
--topic test-topic-perf \
--partitions 3 \
--replication-factor 3 \
--bootstrap-server cluster-kafka-bootstrap:9092먼저, Producer 에 대한 성능 테스트를 진행하겠습니다.
위에서 생성한 토픽을 사용하여 각 100바이트 크기의 1,000만 개의 메세지를 생성합니다.
kubectl exec -it kafka-cli -n kafka -- bin/kafka-producer-perf-test.sh \
--topic test-topic-perf \
--num-records 100000000 \
--throughput -1 \
--producer-props bootstrap.servers=cluster-kafka-bootstrap:9092 \
acks=all \
--record-size 100 \
--print-metrics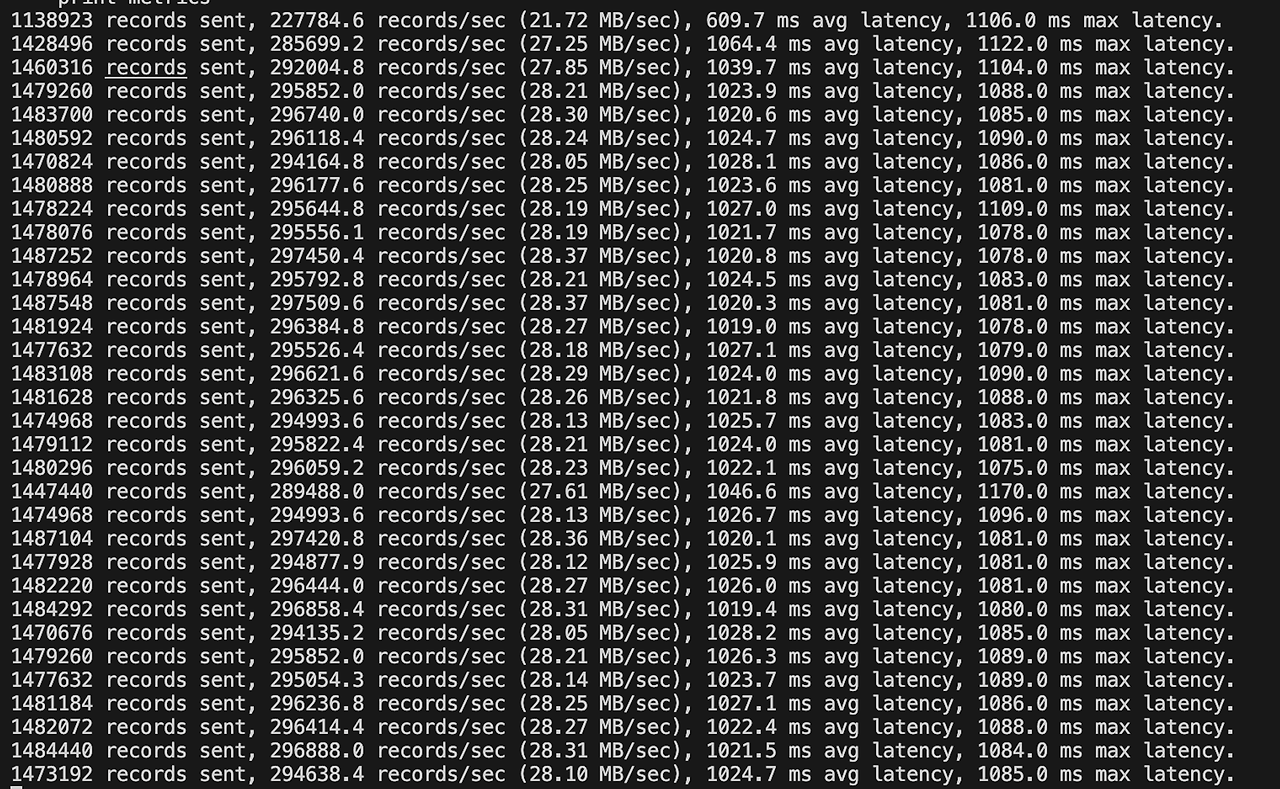
- 초당 약 100만개의 메시지를 전송하였고 초당 약 30만 메시지가 전송되며, 약 1초의 지연이 있음을 확인할 수 있습니다.
이어서 Consumer 성능 테스트를 진행하겠습니다.
kubectl exec -it kafka-cli -n kafka -- bin/kafka-consumer-perf-test.sh \
--topic test-topic-perf \
--messages 100000000 \
--broker-list bootstrap.servers=cluster-kafka-bootstrap.kafka.svc.cluster.local:9092 | \
jq -R .|jq -sr 'map(./",")|transpose|map(join(": "))[]'- 필자의 환경에서 테스트시 메세지 읽기에 대한 결과는 출력받지 못했습니다. Producer에서 1000만개의 메세지를 수집하고 출력하는데 일정 시간이 필요한 것으로 예상됩니다. 참고 문서에서는 다음과 같이 결과가 나온다고 합니다.
Kafka 모니터링
DoEKS 블루프린트는 프로메테우스와 그라파나(대시보드포함)를 배포해줍니다.
아래 명령어를 통해 그라파나에 접속하여 대시보드를 확인하겠습니다.
kubectl port-forward svc/kube-prometheus-stack-grafana 8080:80 -n kube-prometheus-stack로컬 도메인(127.0.0.1:8080)로 접근합니다. 아이디는 admin, 비밀번호는 아래명령어를 통해 확인해주세요.
aws secretsmanager get-secret-value \
--secret-id kafka-on-eks-grafana --query "SecretString" --output text 대시보드 확인시 위 테스트를 진행한 메트릭을 확인할 수 있습니다.
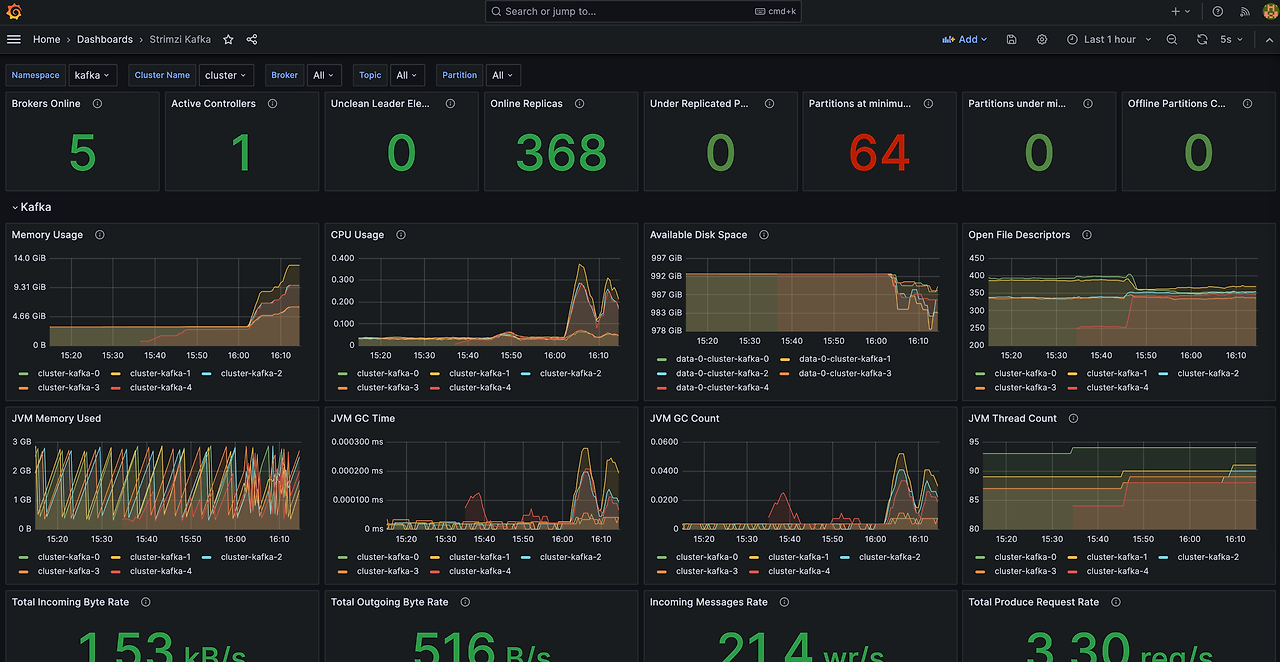
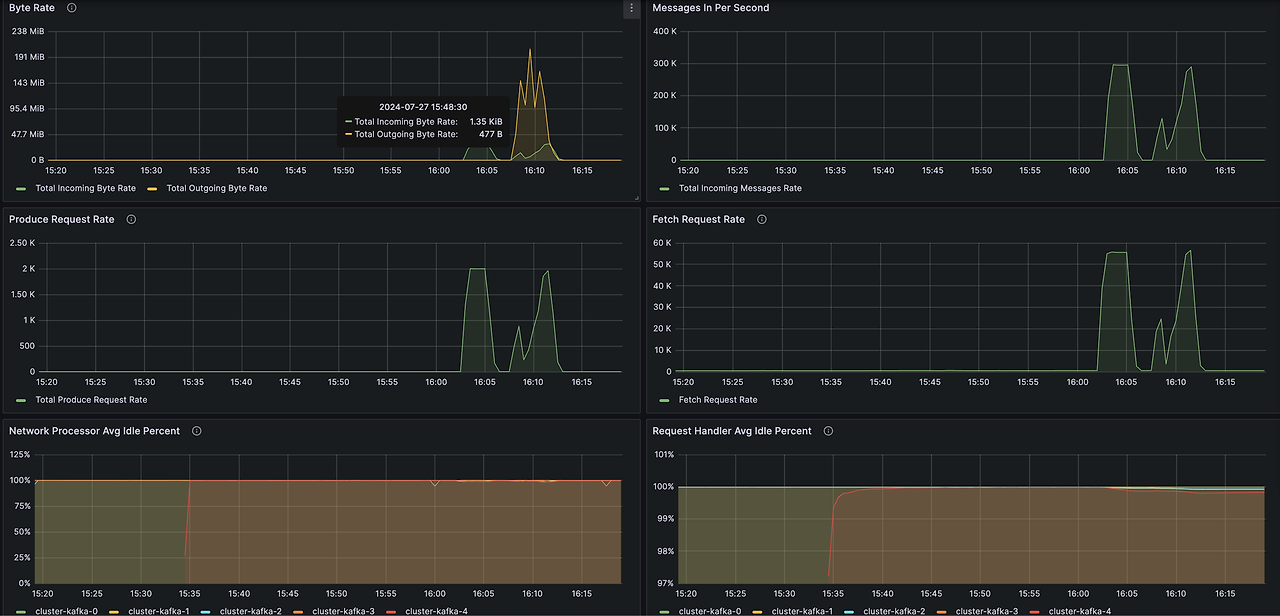
- 왼쪽(Producer), 오른쪽(Consumer) 에 메세지 처리가 균등함을 확인할 수 있습니다.
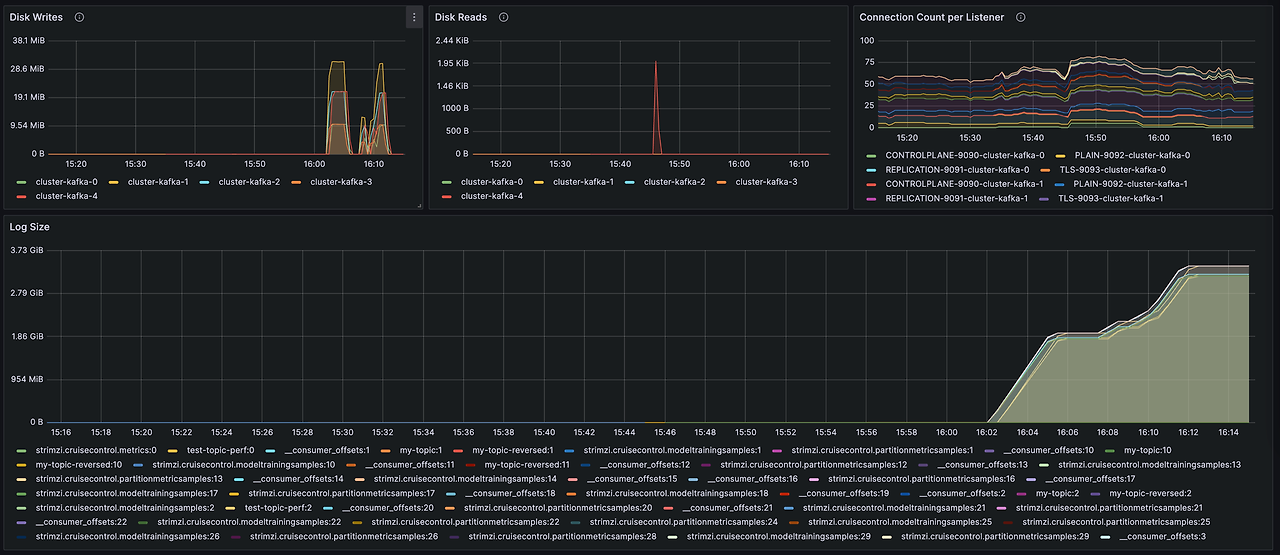
- Kafka는 DISK(EBS)에 저장하며 retention을 통해 로그를 확인할 수 있습니다. 다만, 로그 사이즈가 커진다면 인스턴스 노드에 영향이 갈 수 있으므로 메트릭 확인하여 EBS 자원양을 확인해야 합니다.
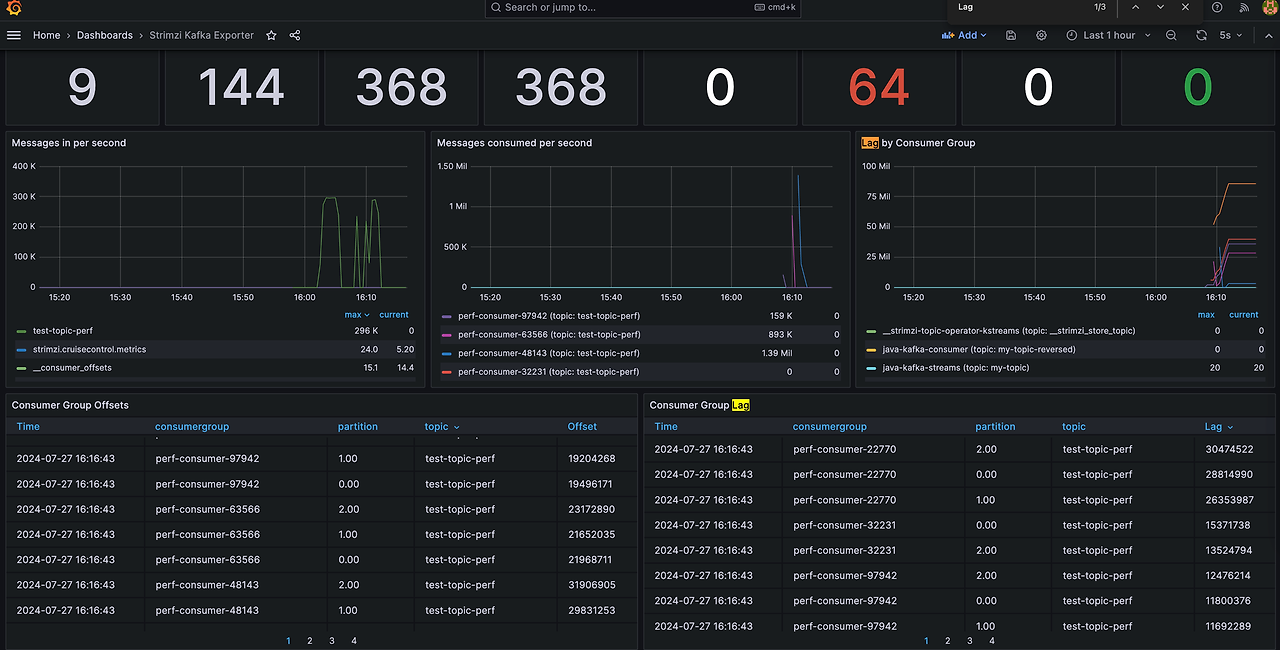
메트릭에서 중요하게 볼 점은 Consumer Group Lag 입니다.
Consumer Group Lag는 소비자(consumer)들이 메시지를 처리한 위치를 관리합니다. 높은 Lag가 있다면 생상된 메세지를 따라가지 못하고 있다는 것을 의미합니다. 아래 대시보드를 확인하면 소비하지 않은 메세지가 약 3천만개가 있는 것을 확인할 수 있습니다. 위 성능 테스트시 메세지 소비가 제대로 안된 것으로 확인되네요.
중단 테스트
Kafka를 EKS에서 구성시 스토리지를 EBS 또는 인스턴스 스토리지에 연결할 수 있습니다. 인스턴스 스토리지가 성능이 확실히 빠르지만, 장애가 발생하여 인스턴스가 교체되는 경우 장애 인스턴스의 메세지가 모두 손실될 가능성이 있습니다. 필자의 이전 블로그에서 해당 내용을 다뤘습니다.
DoEKS에서는 기본적으로 EBS를 통해 스토리지가 연결됩니다. EBS는 EKS addon인 ebs-csi-controller로 관리되며 PVC로 구성되기에 인스턴스와 독립적으로 운영되어 인스턴스가 실패하거나 종료되어도 기존 볼륨을 마운트하여 브로커를 대체할 수 있게 됩니다.
이번 장에서는 노드 장애를 시뮬레이션하여 기존 볼륨의 데이터가 유지되는 지 테스트해보겠습니다.
# 장애 시뮬레이션을 위한 토픽 생성
kubectl exec -it kafka-cli -n kafka -- bin/kafka-topics.sh \
--create \
--topic test-topic-failover \
--partitions 1 \
--replication-factor 3 \
--bootstrap-server cluster-kafka-bootstrap:9092
kubectl exec -it kafka-cli -n kafka -- bin/kafka-topics.sh \
--describe \
--topic test-topic-failover \
--bootstrap-server cluster-kafka-bootstrap:9092
--
Topic: test-topic-failover TopicId: YA9lSEL0TWyuuH-dcskkag PartitionCount: 1 ReplicationFactor: 3 Configs: min.insync.replicas=2,message.format.version=3.0-IV1
Topic: test-topic-failover Partition: 0 Leader: 2 Replicas: 2,1,4 Isr: 2,1,4
# 테스트 메세지 생성
kubectl exec -it kafka-cli -n kafka -- bin/kafka-console-producer.sh \
--topic test-topic-failover \
--bootstrap-server cluster-kafka-bootstrap:9092
위 토픽 확인시 리더가 2로 브로커 2가 리더 역할을 하고 있음을 확인할 수 있습니다.
브로커 2가 띄어진 노드를 찾아 노드를 종료하겠습니다.
# 파드 할당 노드 확인
kubectl -n kafka get pod cluster-kafka-2 -owide
# 노드 드레인
kubectl drain ip-10-1-1-196.ap-northeast-2.compute.internal \
--delete-emptydir-data \
--force \
--ignore-daemonsets
# 인스턴스 종료 명령어
ec2_instance_id=$(aws ec2 describe-instances \
--filters "Name=private-dns-name,Values=ip-10-1-1-196.ap-northeast-2.compute.internal" \
--query 'Reservations[*].Instances[*].{Instance:InstanceId}' \
--output text)
aws ec2 terminate-instances --instance-id ${ec2_instance_id} > /dev/null
종료 후에도 테스트 토픽(test-topic-failover)에 메세지를 확인할 수 있습니다.

EBS 뿐만 아니라 복제본이 있어 데이터를 읽어올 수 있지 않을까 싶습니다.
자원 삭제
필자의 경우 helm 차트의 연동이 안되어 있어 테라폼을 통해 한번에 삭제가 불가능했습니다.
수동으로 helm 차트 삭제 후 인프라를 삭제했습니다.
# 카프카 클러스터 삭제
kubectl delete kafka/cluster -n kafka
# helm 차트 삭제
helm uninstall cluster-autoscaler -n kube-system
helm uninstall cluster-proportional-autoscaler -n kube-system
helm uninstall metrics-server -n kube-system
helm uninstall kube-prometheus-stack -n kube-prometheus-stack
helm uninstall strimzi-operator -n strimzi-kafka-operator 나머지는 AWS 콘솔에서 노드 그룹 > EKS를 삭제하였습니다.
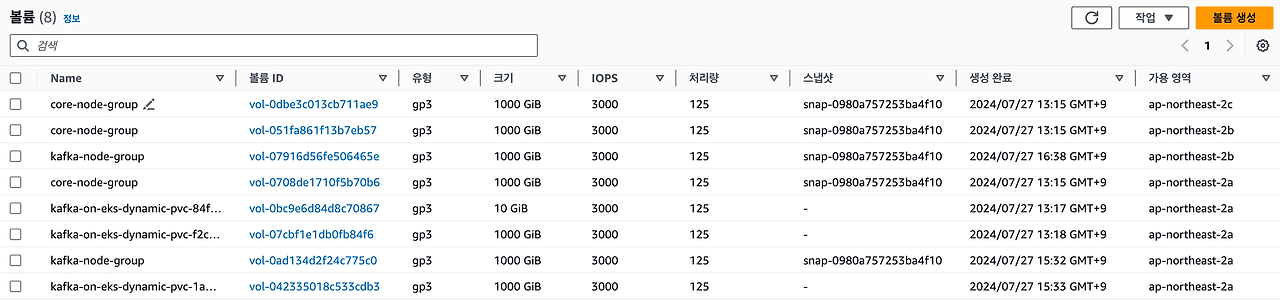
주의할 점은 EBS를 꼭 확인해야 합니다.
PVC에 볼륨이 남아있는 경우에는 그대로 비용이 과금됩니다.
'Cloud' 카테고리의 다른 글
| 컨테이너 구성 이해와 도커 취약점 점검하기 (0) | 2024.08.30 |
|---|---|
| OpenTofu 와 Atlantis 연동하기 (0) | 2024.08.03 |
| EKS에서 Atlantis 구성하기 (0) | 2024.07.14 |
| EKS Karpenter로 부드럽게 Migration 하기 (2) | 2024.07.06 |
| 테라폼 모듈을 활용한 Cloudwatch 알람 자동화(심화) (0) | 2024.06.29 |