Overview
MLOps 플랫폼 Kubeflow의 Karpenter 활용 사례를 참고하여 구성 원리를 알아보겠습니다.
Karpenter, 카펜터

활용 사례를 확인하기 전 카펜터를 확인하겠습니다. 카펜터는 EC2 Fleet 기반의 클러스터 오토스케일러입니다. 다른 클러스터 오토스케일러인 CA(Cluster Autoscaler)와 특징을 비교하면 다음과 같습니다.
|
|
CA(Cluster Autosclaer)
|
Karpenter
|
|
노드 구성 서비스
|
EC2 Auto Scaling Group
|
EC2 Fleet
|
|
노드 구성 관리
|
ASG가 노드 구성
|
Karpenter가 구성
|
|
주요 특징
|
- 단일 인스턴스 타입으로만 노드 그룹 구성 가능 - 노드 증감이 약 5분정도 소요됨(ASG를 통한 노드 검사 및 증설 요청)
|
- 노드 그룹 내 다양한 인스턴스 타입 생성 가능(EC2 fleet 기능) - RI/Spot 구성 가능(EC2 Fleet 기능) - 인스턴스 비용 최적화(노드 통합 및 변경 기능 지원) - 자체 관리로 노드 증감이 약 1분정도 소요
|
카펜터를 사용하면 다양한 인스턴스 타입과 옵션을 다양하게 선택하여 노드 그룹을 구성할 수 있습니다. 카펜터 노드구성(Nodepool) 확인하면 requirements.key 값에서 설정한 옵션들에 대해 따른 인스턴스 타입을 가져와서 노드 그룹을 구성한다고 보시면 됩니다.
requirements:
- key: "karpenter.k8s.aws/instance-category" # 인스턴스 타입 카테고리 설정
operator: In
values: ["c", "m", "r"]
minValues: 2
- key: "karpenter.k8s.aws/instance-family" # 인스턴스 패밀리 설정
operator: In
values: ["m5","m5d","c5","c5d","c4","r4"]
minValues: 5
- key: "karpenter.k8s.aws/instance-cpu" # 인스턴스 CPU 설정
operator: In
values: ["4", "8", "16", "32"]
- key: "karpenter.k8s.aws/instance-hypervisor" # 인스턴스 세대 설정
operator: In
values: ["nitro"]
- key: "karpenter.k8s.aws/instance-generation" # 인스턴스 세대 설정
operator: Gt
values: ["2"]
- key: "topology.kubernetes.io/zone" # 인스턴스 배포 AZ 설정
operator: In
values: ["us-west-2a", "us-west-2b"]
- key: "kubernetes.io/arch" # 인스턴스 아키텍처 설정
operator: In
values: ["arm64", "amd64"]
- key: "karpenter.sh/capacity-type" # 인스턴스 요금 모델 설정
operator: In
values: ["spot", "on-demand"]위의 인스턴스 설정 외에도 노드 중단(Disruption)와 스케쥴링(Scheduling)기능도 지원됩니다. 지원 예제는 아래 kubeflow 활용 예를 통해 확인하겠습니다.
이러한 카펜터의 특징으로 다양한 컴퓨팅 리소스를 신속하게 프로비저닝하고 해제할 수 있는 사례에 적합합니다. AWS 블로그 글을 참고하면 기계 학습 모델 훈련이나 시뮬레이션 실행 등의 사례에 적합하다고 소개하는데요, 적합한 사례에 맞게 MLOps 플랫폼인 Kubeflow에서의 카펜터 사용 예를 확인하겠습니다.

Terraform Kubeflow 배포와 Karpetner 동작 확인
kubeflow 배포는 terraform으로 kubeflow 및 연동 addon 서비스를 자동으로 배포해주는 프로젝트를 참고하였습니다.
해당 프로젝트에서는 테라폼으로 손쉽게 배포가 가능합니다. S3 버킷을 사전에 생성하고 다음의 명령어를 통해 kubeflow 을 배포할 수 있습니다.
# 레파지토리 가져오기
git clone https://github.com/aws-samples/amazon-eks-machine-learning-with-terraform-and-kubeflow.git
cd ~/amazon-eks-machine-learning-with-terraform-and-kubeflow
# S3 버킷생성 - s3 이름을 수정해주세요.
aws s3api create-bucket --region ap-northeast-2 --bucket --create-bucket-configuration LocationConstraint=ap-northeast-2
# kubeflow 배포 - s3 버킷을 수정해주세요
terraform apply -var="import_path=s3:///ml-platform" -var="profile=default" -var="region=ap-northeast-2" -var="cluster_name=ml-eks-cluster" -var='azs=["ap-northeast-2a","ap-northeast-2c"]해당 모듈은 MLOps 플랫폼인 kubeflow 컴포넌트, AWS 스토리지(FSx, EFS) 그리고 오토스케일링(Karpenter)가 자동으로 구성됩니다.
실습에서 구성한 EKS 버전은 1.28이며, karpenter 버전은 0.33.2 입니다.
주의할 점은 Terraform Provider 설정인데요. 배포 지역이 us-west-2 로 설정되어 있어 스토리지 연동(FSx와 S3)시, 아래와 같은 에러가 발생할 수 있습니다.
creating FSx for Lustre Data Repository Association: BadRequest: Amazon FSx is unable to validate access to the S3 bucket. Ensure the IAM role or user you are using has s3:Get*, s3:List* and s3:PutObject permissions to the S3 bucket prefix.
위 에러가 발생한다면 ~/.aws/credetionals 에서 region을 ap-northeast-2 로 설정하여 다시 배포해주세요.
설치는 약 20분정도 소요됩니다.
# 설치 파드 확인
kubectl get pods -n kube-system
kubectl get pods -n kubeflow 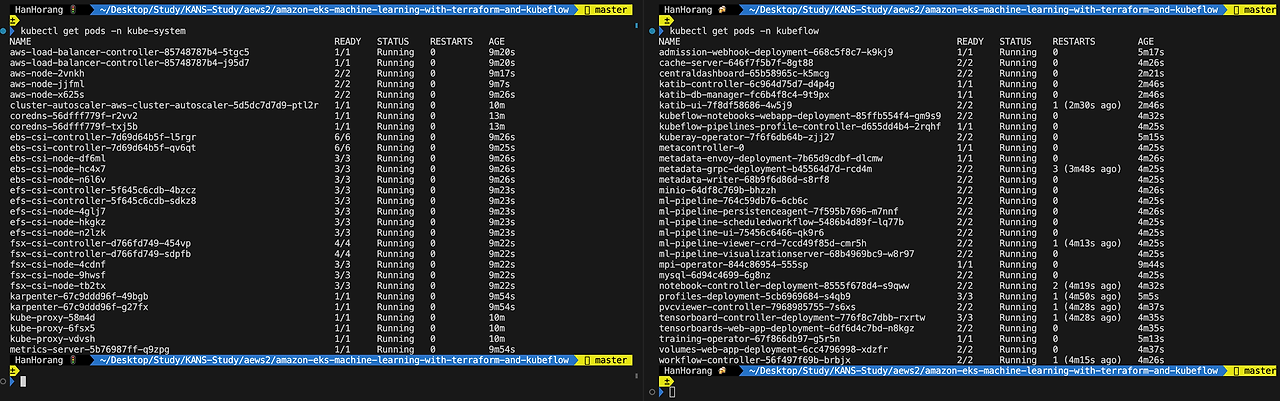
kubeflow 대시보드 접근은 사전 작업을 통해 확인할 수 있습니다.
- istio-ingressgateway 을 통해서 kubeflow dashboard 에 접근하기 위해서는 포트포워딩에 대시보드 FQDN을 입력해야 합니다.
# kubeflow 대시보드 접근
sudo kubectl port-forward svc/istio-ingressgateway -n ingress 443:443
# DNS 접근 도메인 등록
sudo vi /etc/hosts
# 아래 도메인 수정
127.0.0.1 istio-ingressgateway.ingress.svc.cluster.local
# 패스워드 확인
terraform output static_password

Karpenter 사용 확인을 위해 GPU 파드(Jupyter notebook)을 배포하여 노드 구성을 확인하겠습니다.
Kubeflow 대시보드 왼쪽 메뉴 Notebooks > New Notebook 에서 gpu 개수를 설정하여 파드를 배포할 수 있습니다.
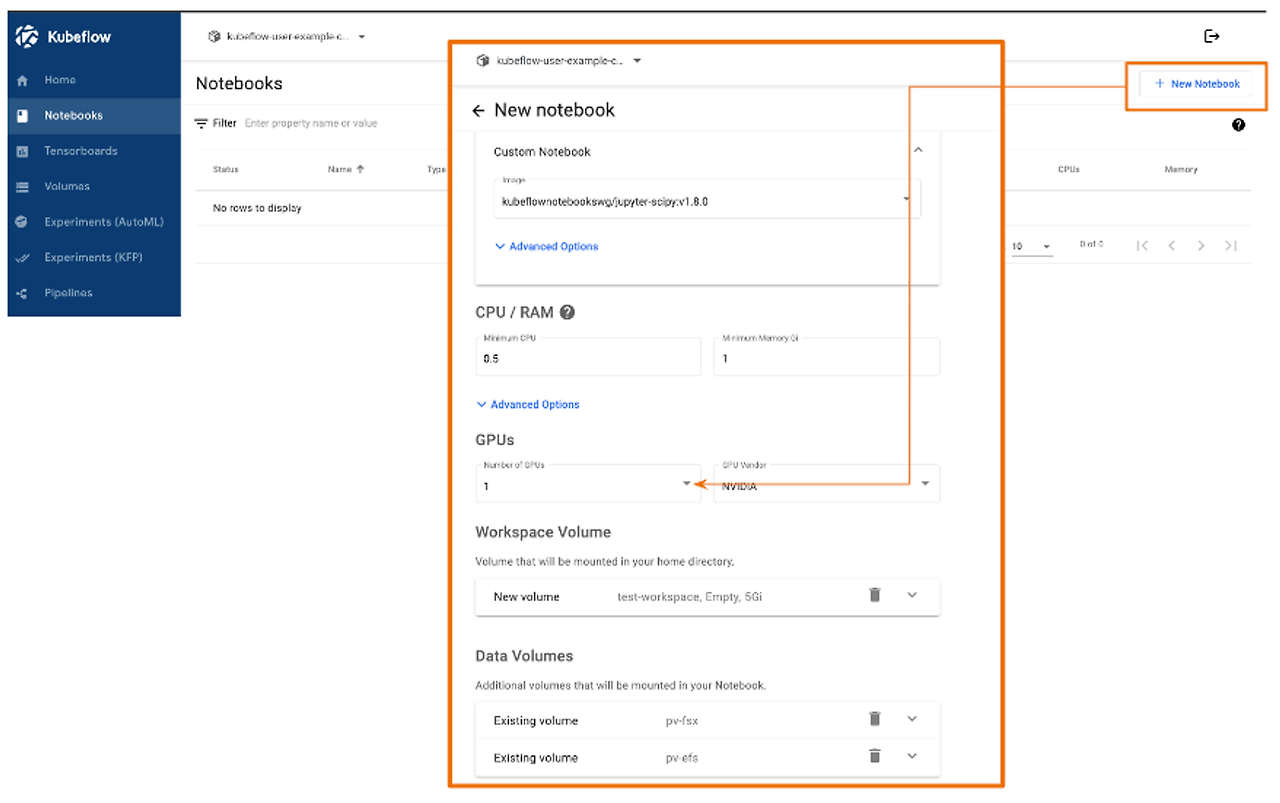
Jupyter notebook을 생성하면 처음에는 GPU 노드가 없어 경고문자가 발생하지만 수 분내 GPU 노드가 생성하여 정상적으로 파드가 할당됩니다.
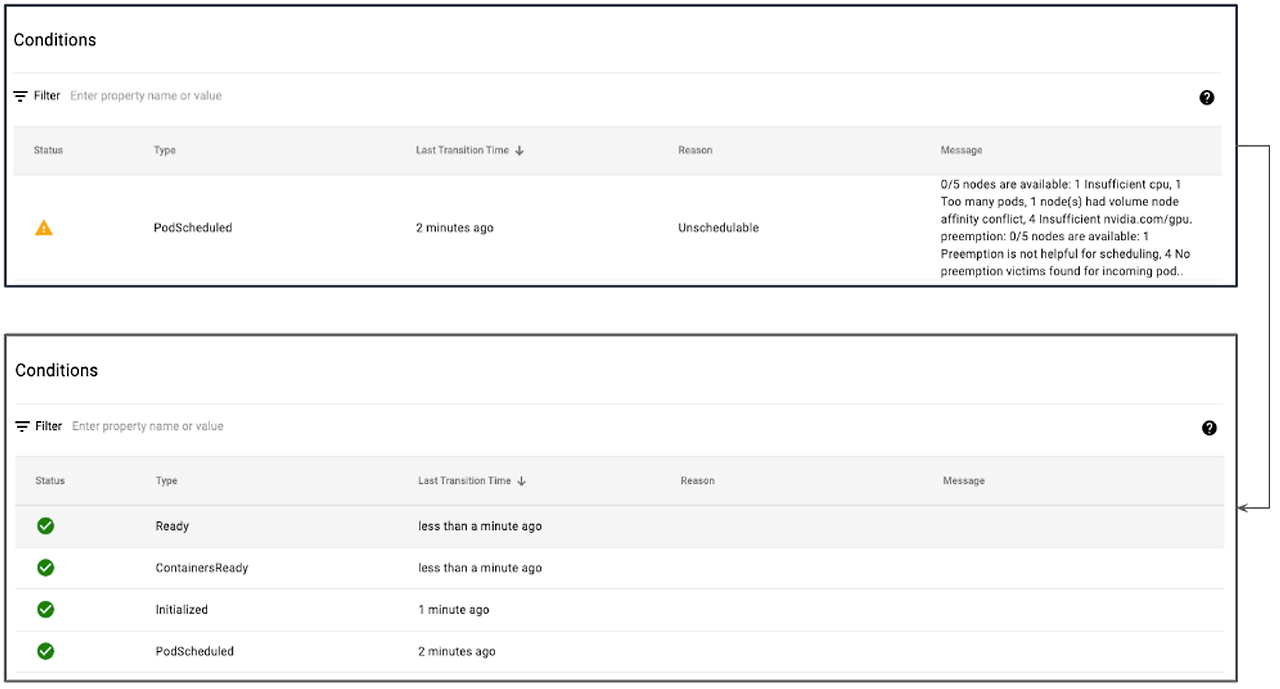
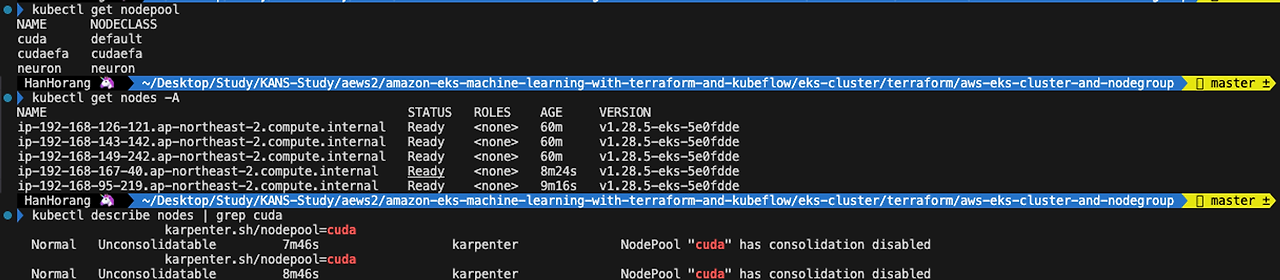

카펜터로 생성된 노드는 할당된 파드를 삭제하면 수분 내 삭제됩니다.

Karpenter 동작 원리 이해
테라폼을 통해 Karpenter 구성이 되어 바로 넘어갈 수 있겠지만 고려할 것이 많습니다.
동작 원리 이해없이 실무에 도입한다면 노드가 갑자기 통합되어 서비스 중인 파드가 중단이 일어날 수 있으며, 다른 시스템 적용시 어려움이 많을 것이라 예상됩니다. 앞서 설치한 모듈의 테라폼 코드를 통해 Karpenter 설치와 동작 원리를 확인하겠습니다.
Karpetner 설치
Karpetner을 사용하기 위해서는 사전 작업이 필요합니다. EC2 Fleet을 사용하기 위해 IAM 정책을 생성하여 EKS role 및 Serviceaccount 연동(IRSA)이 필요하며 또한, Karpenter 노드를 어디에 배포할 것인 지에 대한 서브넷 태그 설정이 필요합니다. kubeflow 모듈에서는 karpetner 구성을 위해 resource IAM, EKS aws-auth, subnet 설정을 하였습니다.

Karpenter는 helm 차트를 통해 배포하였습니다.
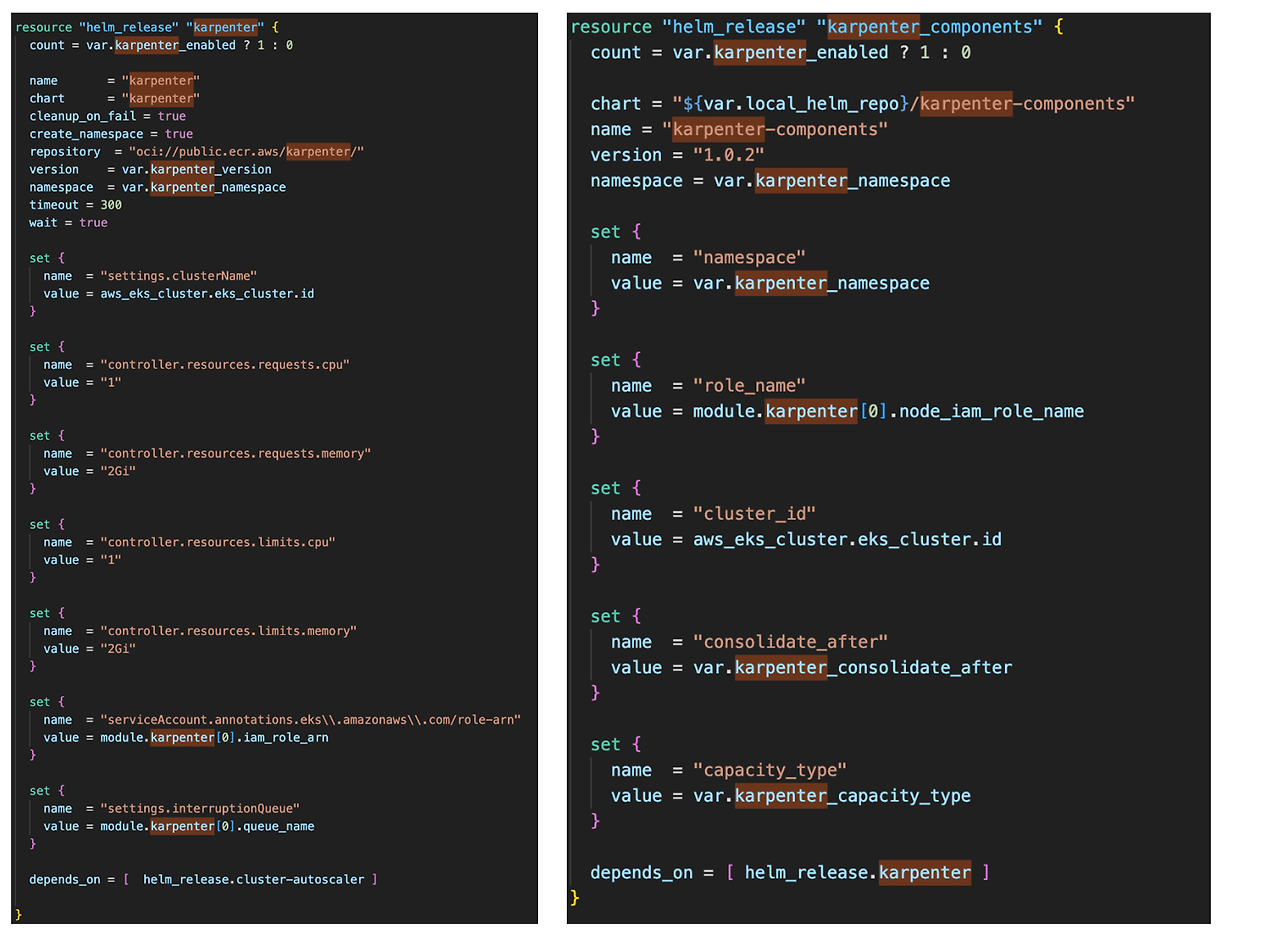
테라폼에서 helm 차트 values 설정 값을 보기에는 가독성이 떨어지는데요, 아래 명령어를 통해 values를 값을 확인할 수 있습니다.
helm get values karpenter -n kube-system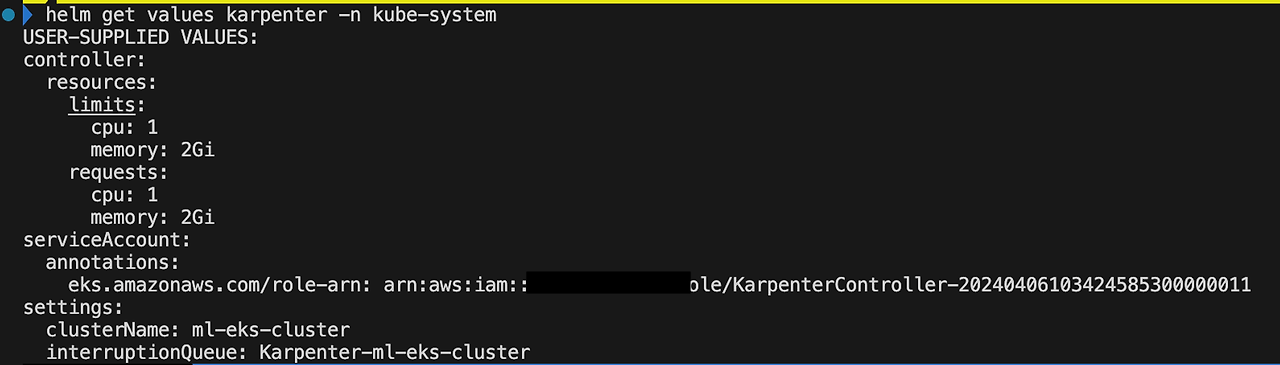
또한, Karpnter 차트 배포시 EKS 버전 호환성을 고려해야합니다.

Karpenter는 Kubernetes Custom Resource Definitions(CRD)을 통해 기능을 지원하지만, Kubernetes 버전 < 1.25에서는 지원되지 않습니다. 만약 이전 버전의 Kubernetes를 사용 중이라면, Karpenter 입장 웹후크를 대신 사용해야 합니다. 이 웹후크를 활성화하기 위해서는 Karpenter Helm 차트를 적용할 때 --set webhook.enabled=true를 사용해야 합니다.
스케쥴링 이해
위 실습에서 GPU 사용 파드 요청시 g4dn.xlarge 타입의 인스턴스가 2대 증설됨을 확인했습니다. 증설된 인스턴스 타입과 대수는 Karpenter NodePool에서 확인이 가능합니다. 실습에서 생성한 NodePool은 다음과 같습니다.
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: cuda
namespace: {{ .Values.namespace }}
spec:
disruption: # 1
consolidationPolicy: WhenEmpty
consolidateAfter: {{ .Values.consolidate_after }}
template:
spec:
nodeClassRef:
name: default
requirements:
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: [ {{ .Values.capacity_type }} ]
- key: node.kubernetes.io/instance-type # 2
operator: In
values:
- "g4dn.xlarge"
- "g4dn.2xlarge"
- "g4dn.4xlarge"
- "g4dn.8xlarge"
- "g4dn.12xlarge"
- "g4dn.16xlarge"
- "g5.xlarge"
- "g5.2xlarge"
...
taints: # 3
- key: nvidia.com/gpu
value: "true"
effect: NoSchedule
startupTaints:
- key: fsx.csi.aws.com/agent-not-ready
effect: NoExecute
limits:
nvidia.com/gpu: 1024
disruption : 노드 통합에 대한 옵션을 정의합니다. 위 정의에서는 파드가 비어있을 때 일정 시간(600s)가 지나면 노드가 통합되도록 설정되었습니다.
node.kubernetes.io/instance-type : 위 Values을 확인하면 GPU 인스턴스 타입이 여러 정의되어 있습니다. 노드 선정 우선순위는 낮은 가격이나 낮은 중단률에 따라 결정됩니다.

- 타입이 on-demand , spot 으로 구분됩니다. kubeflow 는 on-demand 타입을 사용하며 낮은 가격의 인스턴스를 우선 순위로 선택하여 선정합니다. 그렇다면 가장 가격이 저렴한 g4dn.xlarge 타입만 프로비저닝되는 것도 아닙니다. pending된 파드의 reqeust 양에 따라 노드 타입 후보를 먼저 선정하고 그 중에서 가격이 저렴한 인스턴스를 선택하게 됩니다
taints : 카펜터 워크로드 구성으로 쿠버네티스의 파드 할당 전략을 사용할 수 있습니다. kubeflow에서는 taints를 통해 nvidia.com/gpu 의 파드만 해당 노드 그룹에 배치하게 만들도록 구성하였습니다. GPU 파드로 구성한 jupyter 파드를 확인하면 taints 값이 설정된 노드에만 배치하도록 설정한 것을 확인할 수 있습니다.

kubeflow에서는 GPU를 사용하는 노드에서만 카펜터를 통해 프로비저닝되도록 Nodepool을 구성하였는데요. 이는 GPU 파드가 없는 경우에는 노드 풀을 0으로 유지하다가 파드가 스케쥴링될 때만 GPU 노드를 구성하도록 설정하였기 때문입니다.
카펜터 로그를 확인하면 파드 프로비저닝되는 과정을 확인할 수 있습니다.
kubectl logs deploy/karpenter -n kube-system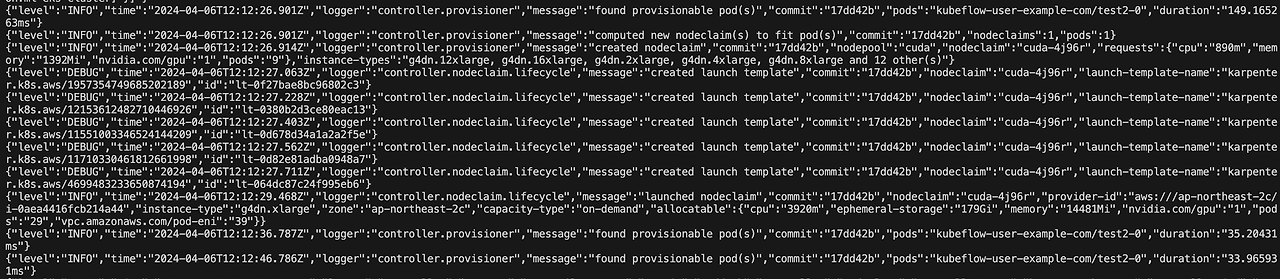
카펜터 차트의 default 로그 레벨은 Info로 위 로그가 확인이 안됩니다.
헬름 값을 업데이트하여 다시 배포해주세요. 차트 업데이트는 helm_release karpenter 의 설정 값을 수정하거나 배포된 헬름 차트를 수정하여 업데이트하면 됩니다.
# 차트 값 가져오기
helm get values karpenter -n kube-system > karpenter-values.yaml
# 차트 수정
vi karpenter-values.yaml
---
USER-SUPPLIED VALUES:
controller:
resources:
limits:
cpu: 1
memory: 2Gi
requests:
cpu: 1
memory: 2Gi
serviceAccount:
annotations:
eks.amazonaws.com/role-arn: 0000000000
logLevel: debug # 로그 레벨 추가
settings:
clusterName: ml-eks-cluster
interruptionQueue: Karpenter-ml-eks-cluster
# 차트 업데이트
helm upgrade --install --namespace kube-system karpenter oci://public.ecr.aws/karpenter/karpenter -f karpenter-values.yaml
Kubeflow 삭제
활용 예로 사용한 kubeflow 모듈은 아래 명령어를 통해 삭제해주세요.
또한, 로컬호스트에 대해 원복이 필요합니다.
# 모듈 삭제
# 변수 마지막 s3 버킷을 수정해주세요
terraform destroy -var="profile=default" -var="region=ap-northeast-2" -var="cluster_name=ml-eks-cluster" -var='azs=["ap-northeast-2a","ap-northeast-2c"]' -var="import_path=s3://<S3-bucket-Name>/ml-platform"
# DNS 접근 도메인 원복
sudo vi /etc/hosts
# 아래 도메인 수정
127.0.0.1 localhost
'Cloud Tech' 카테고리의 다른 글
| 쿠버네티스 오픈소스, Kyverno 이해하기 (0) | 2024.04.12 |
|---|---|
| Karpenter 고려사항 (0) | 2024.04.07 |
| Terraform AWS Observability Accelerator와 멀티클러스터 Observability 구성하기 (1) | 2024.03.31 |
| AWS 스토리지 이해와 EKS에서 Kafka를 위한 스토리지 고려사항 (0) | 2024.03.23 |
| Istio On EKS (0) | 2024.03.16 |