Overview
카펜터에 대해 검색하면 여러 도입 사례를 확인할 수 있습니다. 도입 사례들을 참고하여 운영 고려사항들을 정리하겠습니다.
노드 자체 제어 기능 비활성화
Karpenter에서는 비용 감소화를 목적으로 노드를 자체 중단 제어합니다. 다만, 파드 레벨에서 라이프사이클이 적용되지 않은 상태라면 순단이 발생할 수 있습니다. 파드 종료 라이프사이클로 prestop 이나 PDB 을 설정하는 방법은 제니퍼소프트 테크 블로그 글을 참고해주세요.
다만, 상황에 따라 PDB와 라이프사이클 설정이 할 수 없는 상황이라면 중단 제어를 자체적으로 중지해야 합니다.
아래 NodePool annotation을 통해 중지 제어를 중지할 수 있습니다.
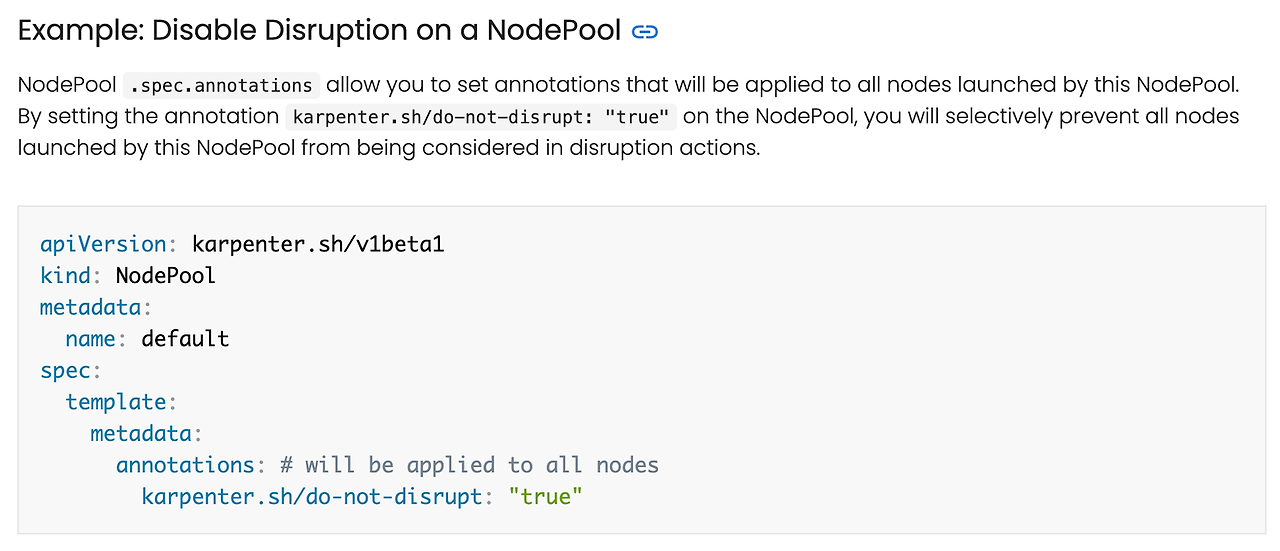
동일한 이유로 Drift 기능의 비활성화도 고려해야 합니다.
Drift는 Karpenter NodePool, NodeClass 에 대한 업데이트 내용을 기존 운영 중인 노드에도 적용하는 기능입니다. Karpenter 0.33 버전부터 기본적으로 활성화되어 있어 비활성화가 필요합니다. 차트 배포시 아래의 옵션을 통해 비활성화를 설정할 수 있습니다.
vi karpenter-values.yaml
---
USER-SUPPLIED VALUES:
controller:
resources:
limits:
cpu: 1
memory: 2Gi
requests:
cpu: 1
memory: 2Gi
serviceAccount:
annotations:
eks.amazonaws.com/role-arn: 0000000000
settings:
clusterName: ml-eks-cluster
interruptionQueue: Karpenter-ml-eks-cluster
featureGates: # 추가
drift: falase # 추가
# 차트 업데이트
helm upgrade --install --namespace kube-system karpenter oci://public.ecr.aws/karpenter/karpenter -f karpenter-values.yaml
RI / Saving Plan 적용 인스턴스 우선순위 설정하기
카펜터에서는 비용 최적화 정책으로 노드를 선정합니다. 다만 RI / Saving Plan이 적용된 노드들이 있다면 노드 후보 선정을 다시 구성해야 하는데요. 가중치를 통해 특정 인스턴스 타입을 우선 순위로 선정하도록 할 수 있습니다. 공식 문서를 참고하면 NodePool 을 나눠 구성하고 Weight 설정을 통해 우선순위를 설정한 것을 확인할 수 있습니다. 또한 RI / Saving Plan 도 인스턴스 개수를 설정하기에 limit을 설정하여 예상 범위내에서만 노드가 구성되도록 설정한 것을 확인할 수 있습니다.

자체 AMI 을 통한 NodePool 구성
보안상의 이유로 자체 AMI가 필요한 경우 spec.amiSelectorTerms 옵션을 통해 AMI 를 지정하여 NodeClass을 구성할 수 있습니다.
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
# Required, resolves a default ami and userdata
amiFamily: AL2
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}"
environment: test
- id: subnet-09fa4a0a8f233a921
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}"
environment: test
- name: my-security-group
- id: sg-063d7acfb4b06c82c
amiSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}"
environment: prod
- id: ami-052c9ea013e6e3567 # 자체 AMI 구성공식문서를 참고하면 AMI 소유자나 정규표현식을 통해 AMI를 설정할 수 있습니다. 그리고 서브넷, 보안 그룹 설정 옵션도 제공하여 필요한 VPC와 보안 그룹에 맞춰 노드를 구성할 수 있습니다.
CA → Karpenter 마이그레이션
기존 노드 그룹을 CA에서 Karpenter로 마이그레이션 한다는 의미는 노드 구성을 ASG에서 EC2 Fleet으로 전환한다는 의미입니다. 공식 문서를 확인하면 Karpenter 노드 그룹을 새로 생성하여 기존 노드 그룹을 Drain 하여 옮기는 과정을 소개하고 있습니다.

기존 노드 그룹에 대해 Karpenter을 구성하기 위해 다음의 과정 수행합니다.
- IAM 정책 생성
- 서브넷, 보안 그룹 태그 설정
- EKS aws-auth 업데이트
- Karpenter 배포 및 노드 설정
- CA 비활성화 및 기존 노드그룹 숫자 수정
유의해야 할 점은 Karpenter 배포 스케쥴링입니다. Karpenter가 관리하는 노드 풀에 속하지 않는 기존 노드 그룹에 꼭 Karpenter 파드를 배포해야 합니다. 기존 노드를 drain시 파드의 pending 상태를 확인해야 하기 때문입니다. Karpenter deployment 에서 파드 스케쥴링을 다음과 같이 수정하면 기존 노드 그룹에 배포되도록 설정할 수 있습니다.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: karpenter.sh/nodepool
operator: DoesNotExist
- matchExpressions:
- key: eks.amazonaws.com/nodegroup
operator: In
values:
- ${NODEGROUP} # 기존 노드 그룹
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: "kubernetes.io/hostname"
Spot Interruption
카펜터에서는 AWS 인스턴스에 대해 다음 이벤트를 감지하여 노드를 미리 corden & Drain 하는 기능을 제공합니다.

특히 스팟 인스턴스의 경우 2분 전 알람을 통해 Karpenter에서 자체적으로 드레인하여 다른 노드에 스케쥴링 될 수 있도록 하는 기능을 제공하는데요. 이 기능을 활성화 하기 위해서는 Interruption-handling 활성화가 필요합니다. 카펜터 구성 배포시 settings.interruptionQueue 을 설정하면 AWS SQS가 생성되어 카펜터에서 메세지를 풀링할 수 있도록 구성됩니다.
helm upgrade --install karpenter oci://public.ecr.aws/karpenter/karpenter --version "${KARPENTER_VERSION}" --namespace "${KARPENTER_NAMESPACE}" --create-namespace \
--set "settings.clusterName=${CLUSTER_NAME}" \
--set "settings.interruptionQueue=${CLUSTER_NAME}" \
--set controller.resources.requests.cpu=1 \
--set controller.resources.requests.memory=1Gi \
--set controller.resources.limits.cpu=1 \
--set controller.resources.limits.memory=1Gi \
--wait
2분 전 알람이 부족하다면 NTH(Node Termination Handler) 를 도입하여 Spot 인스턴스에 대해 재조정 권고 사항이 오면 drain을 할 수 있습니다. 다만 Karpenter는 Spot 인스턴스의 재조정(rebalance) 권고에 따른 드레이닝(drain, 즉, 작업을 안전하게 옮기고 노드를 종료하는 과정)과 종료를 지원하지 않습니다.
NTH를 통해 노드가 drain 되었다면, Karpenter는 해당 노드가 왜 종료되었는지, 즉, 재조정 권고 때문인지 알지 못합니다. 이로 인해 Karpenter가 방금 제거된 인스턴스 유형을 다시 시작할 수 있으며, 이는 다시 재조정 권고를 받을 수 있음을 의미합니다. 결과적으로, NTH가 노드를 지속적으로 제거하고 Karpenter가 같은 유형의 인스턴스를 반복적으로 재시작하는 상황이 발생할 수 있다고 합니다. 워크로드에 따라 도입을 검토하면 좋을 것 같습니다.

'Cloud' 카테고리의 다른 글
| SonarQube를 활용한 EKS CleanCode CI /CD 파이프라인 구축하기 (0) | 2024.04.20 |
|---|---|
| 쿠버네티스 오픈소스, Kyverno 이해하기 (0) | 2024.04.12 |
| Kubeflow로 보는 Karpenter (0) | 2024.04.07 |
| Terraform AWS Observability Accelerator와 멀티클러스터 Observability 구성하기 (1) | 2024.03.31 |
| AWS 스토리지 이해와 EKS에서 Kafka를 위한 스토리지 고려사항 (0) | 2024.03.23 |