작년 ChatGPT를 시작으로 생성형 AI 기술이 각광받고 있습니다. 필자는 ChatGPT AI 기술인 LLM(대형 언어 모델)를 관심있게 보고 있었는데 AWSKRUG 모임에서 제공해주신 발표를 통해 LLM 기술을 쉽게 접할 수 있었습니다. 특히 최근 마곡 소모임에서 테라폼 공식 문서를 학습하고, 평가해주는 모델을 생성하는 것을 보고 인상 깊게 생각했는데요.
그렇다면 앤서블(Ansible) 을 LLM로 학습시켜 돌려보면 어떨까 라는 생각으로 해당 글을 작성하게 되었습니다. 앤서블을 LLM을 통해 학습시켜야겠다는 생각은 앤서블 최신 버전에 따른 모듈 변경이였는데요. 오픈소스 프로젝트를 주로 보는 필자 입장으로 보자면 다음의 과정을 통해 LLM의 필요성을 느꼈습니다.
- 앤서블 최신 버전 업데이트로 모듈과 옵션이 변경됨
- 기존 앤서블 오픈소스 프로젝트가 최신 버전에서 환경 설정등의 이유로 오류 발생
- 앤서블 기존과 최신 버전의 사용 선택에서 호환성과 기능면으로 최신 버전을 선택할 수 밖에 없음
- 기존 앤서블 오픈소스 프로젝트 코드에 대한 최신 버전 마이그레이션 필요
- 최신 버전에 대한 자료글은 공식 문서를 참고할 수 있으나 내용이 너무 방대함
- ChatGPT는 최근 자료에 대한 학습이 없고, 학습 기능을 지원하지 않습니다.
LLM 모델 구성을 위해 AWS Bedrock을 사용하였습니다. AWS Bedrock는 완전 관리형 생성형 AI 서비스입니다. 소개는 AWS 공식문서를 참고해주세요. Bedrock을 사용한 아키텍처는 다음과 같이 구성했습니다.
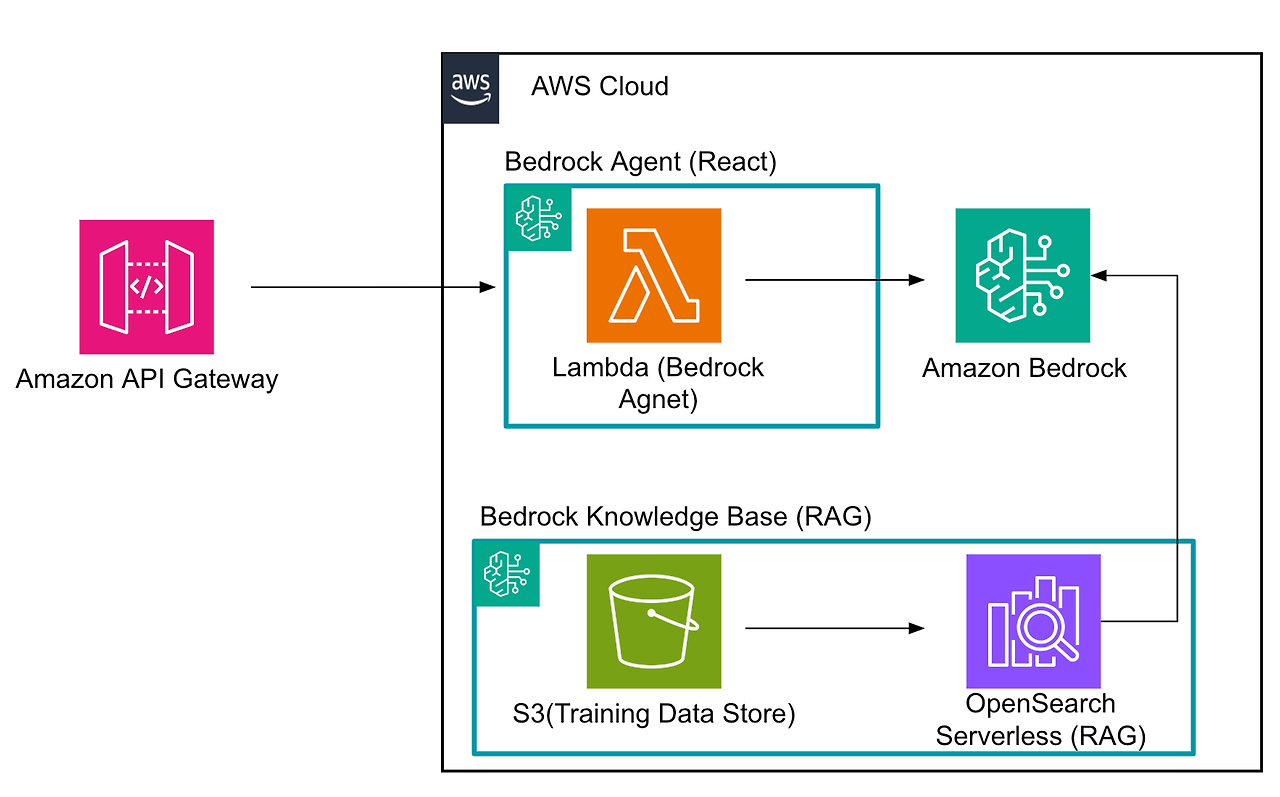
Bedrock는 모델 평가를 수치를 높이기 위한 기술이 제공됩니다. 필자도 모델 평가를 높이기 위해 Recat, RAG를 사용하였습니다. 각 기술에 대한 설명과 사용 방법은 하단에 기술하겠습니다.
구성 서비스(lambda, openserach, bedrock)은 서버리스로 구성이 가능합니다. 서버리스는 사용하지 않으면 비용이 부과되지 않는 것이 핵심인데요. Opensearch serverless 는 구성 유지 비용 요금이 발생합니다. 사용하지 않는다면, 전부 삭제하는 것을 추천드립니다.
Bedrock는 모델별로 지원되는 리전이 다릅니다. 특히 knowledge base 지원 리전은 미국 동부, 서부만 가능합니다. 필자는 us-east-1 리전에서 구성했습니다.
React
ReAct(Reason + Act)는 구조화된 템플릿을 LLM에 제공하여 추론 능력과 모델 평가를 향상시키는 Prompt Engineering 기법입니다. 구조화된 템플릿은 질문, 사고, 조치, 관찰로 구성됩니다.

- 질문, QA : 사용자의 요청 작업 또는 해결해야하는 문제
- 사고, Thoutgt : 문제를 해결하고 취해야할 조치를 식별하는 방법을 모델에게 제시
- 조치, Act : 모델이 간접적으로 호출할 수 있는 API
- 관찰, obs : 조치를 수행한 결과
논문 사례를 보고 기법을 요약하면, 사용자에게 질문을 받고 자체적으로 사고하여 더 높은 답변을 얻기 위해 구성한 질문을 구성하여 LLM 모델에 전달한다고 보시면 되겠습니다.
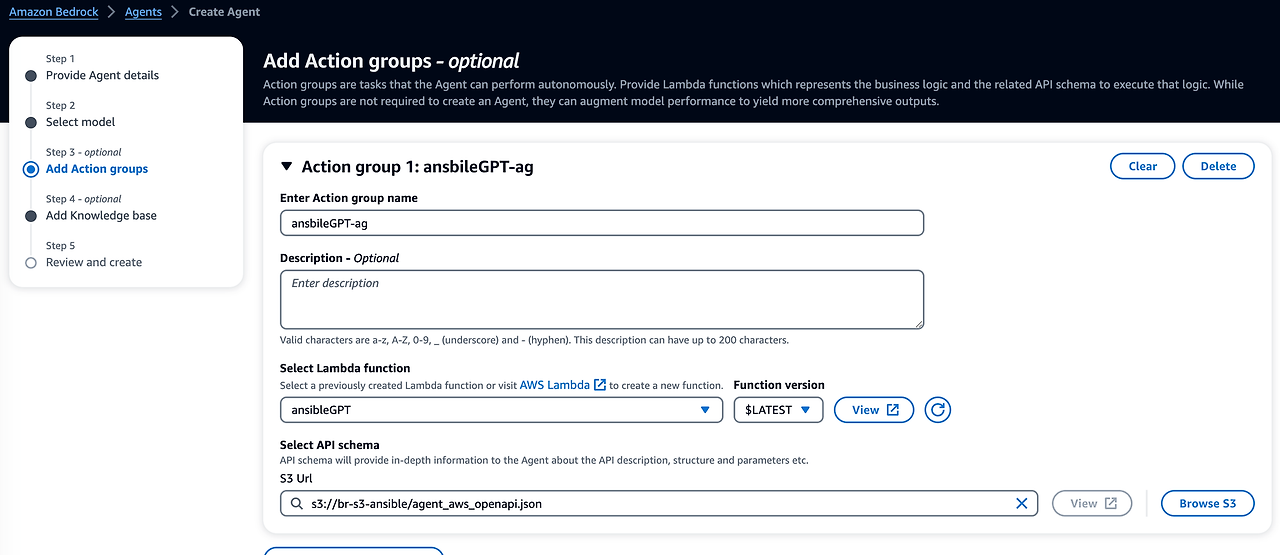
Bedrock에서는 react를 Bedrock Agent(Action Group)을 통해 구현할 수 있습니다. Action Group 구성을 확인하면 람다와 스키마를 구성해야 합니다. 설정한 람다와 스키마(아래 2번째 openAPI spec)를 통한 react 과정은 아래 2번째 사진과 같습니다.
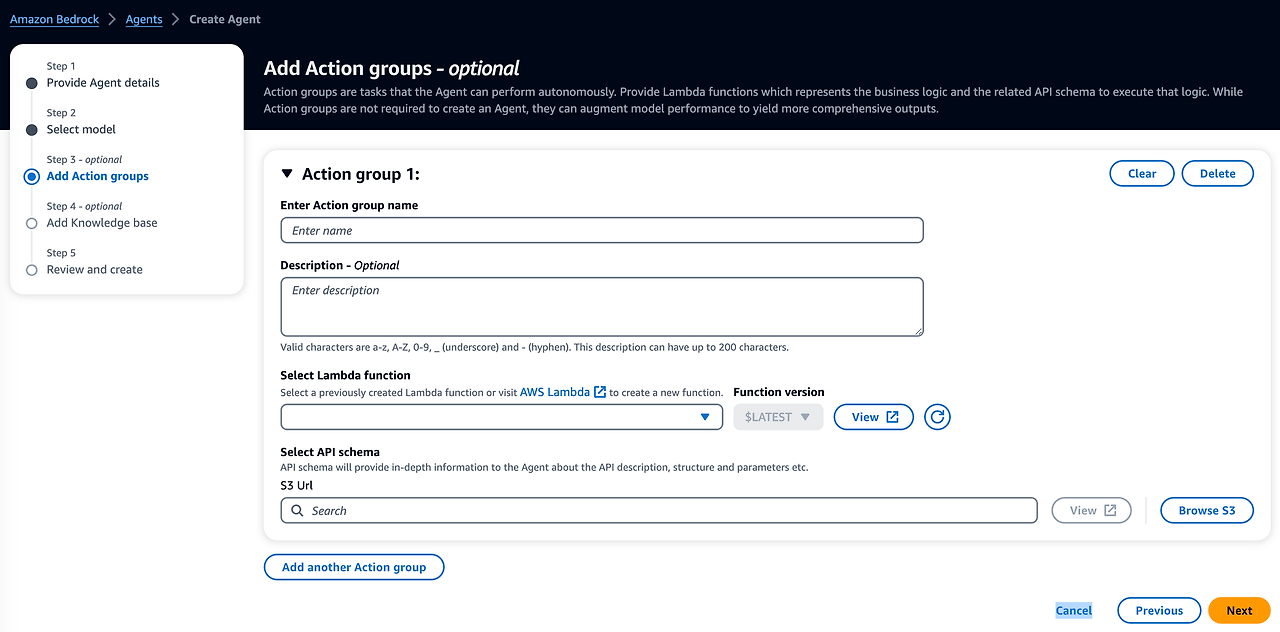
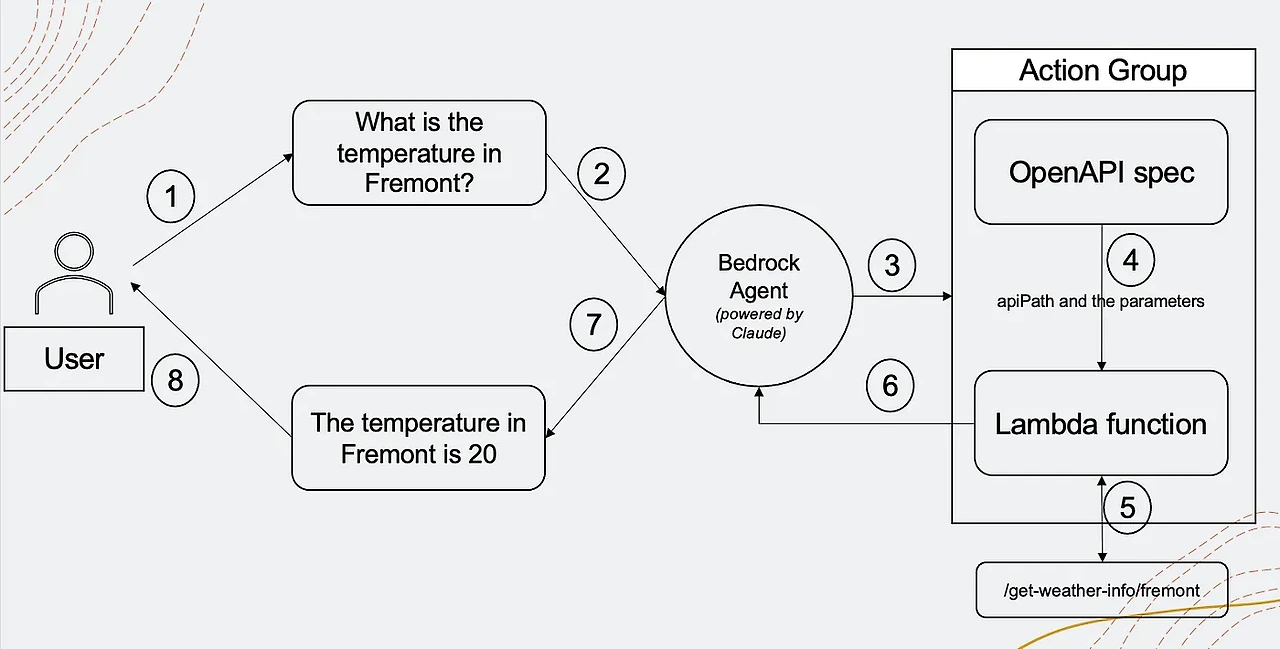
핵심 과정은 4,5 번 과정입니다. 위 react와 동일하게 구조화된 템플릿을 openAPI spec을 통해 입력받아 사고(Thougth)하고 람다 함수를 통해 모델을 간접접으로 호출(조치,Act) 하게 됩니다.
람다 함수와 템플릿 예제는 공식 문서나 github을 통해 참고하여 구성하는 것을 추천드립니다. 목록별 정리 리스트를 참고해주세요.
필자는 코드 제네레이터 구성을 위해 최대한 예제인 AWS 최적화 아키텍처 봇을 선택하여 작업 그룹을 구성했습니다. 템플릿은 agent_aws_openapi.json 을 s3에 업로드하시면 되고, 람다 함수 구성은 컨테이너 말아 올려야합니다.
람다 함수 구성
git clone https://github.com/build-on-aws/amazon-bedrock-agents-quickstart.git
cd amazon-bedrock-agents-quickstartECR 레파지토리 생성한 다음, View Push Commands 를 통해 컨테이너 이미지 업로드
RAG
RAG(Retrieval-Augmented Generation, 검색증강생성)는 사전 훈련된 언어 모델의 기능과 검색 기반 접근 방식을 결합하여 더 많은 정보와 정확한 응답을 생성하는 프레임워크입니다. 쉽게 말하자면, LLM에 모델에 추가 데이터를 학습시켜 투명성을 높이고 할루시네이션을 최소화하기 위한 과정이라 이해하시면 됩니다. 할루시네이션이란 모델의 훈련 데이터에 명시적으로 존재하지 않는 정보를 '상상'하여 응답하는 경우입니다. 가끔 ChatGPT가 전혀 엉뚱한 답변을 할 때가 있는데 이를 피하기 위한 과정이라고 생각하시면 됩니다.
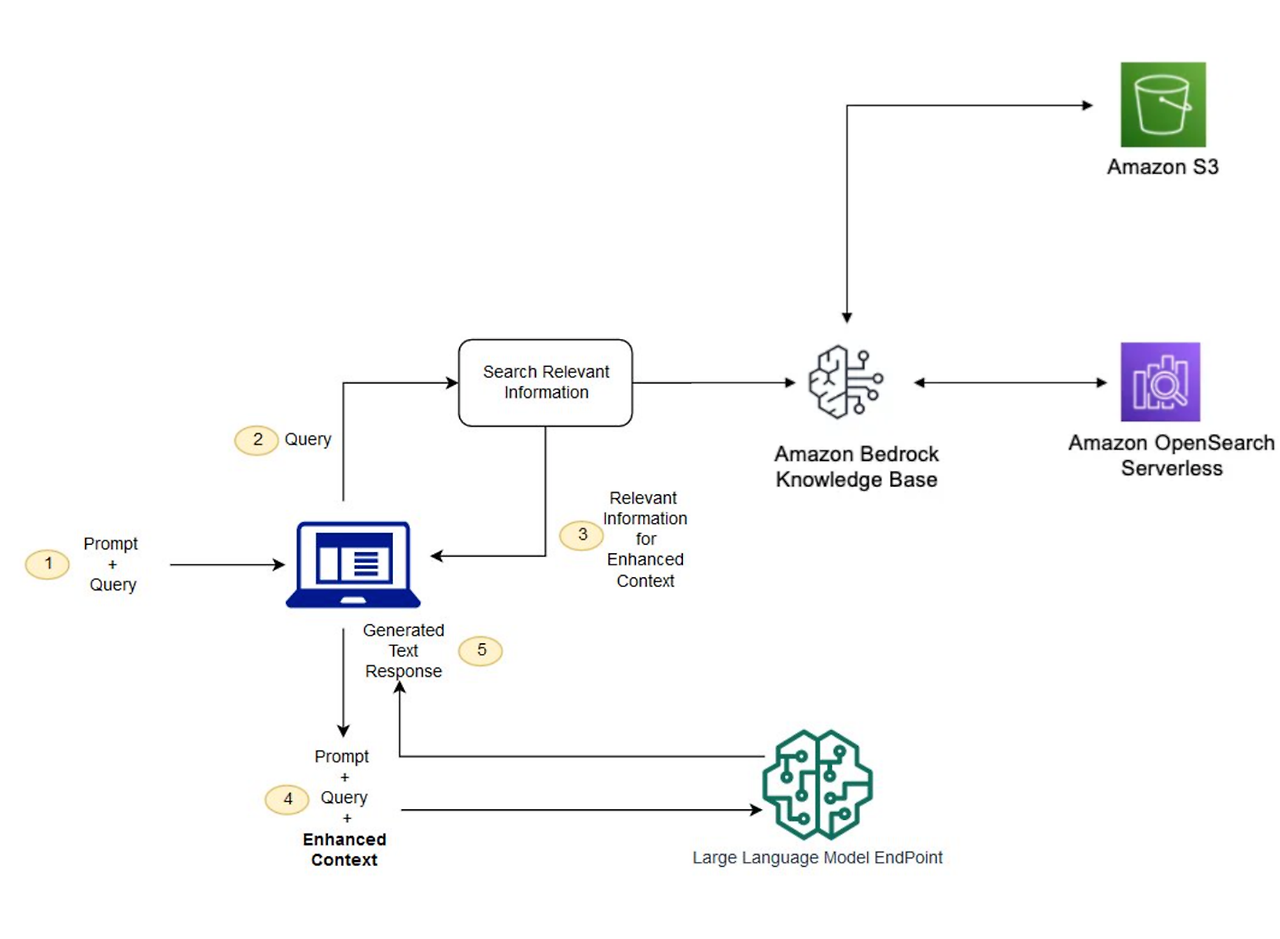
상단 AWS Bedrock Knowledge Base 가 RAG 과정을 진행합니다. 깊이 아키텍처를 보면 학습 데이터를 임베딩(텍스트 데이터를 고차원 벡터데이터로 변환)하고 벡터 데이터베이스에 저장합니다. 벡터 데이터베이스는 검색 엔진(위 그림 AWS Opensearch Serverless)을 사용합니다. 과정으로 보면, 입력 쿼리를 가져와 임베딩을 사용하여 이를 벡터로 변환한 다음 벡터 데이터베이스를 검색하여 관련 문서를 검색하여 쿼리와 의미상 관련된 문서나 구절을 선택하여 추가 컨텍스트로 원래 쿼리를 보강하는 과정입니다.
AWS Bedrock Knowledge Base 를 구현하기 위해서는 먼저 S3에 학습 데이터를 설정해야 합니다. AWS 공식 문서에서 인식하는 데이터 형식은 다음과 같습니다.
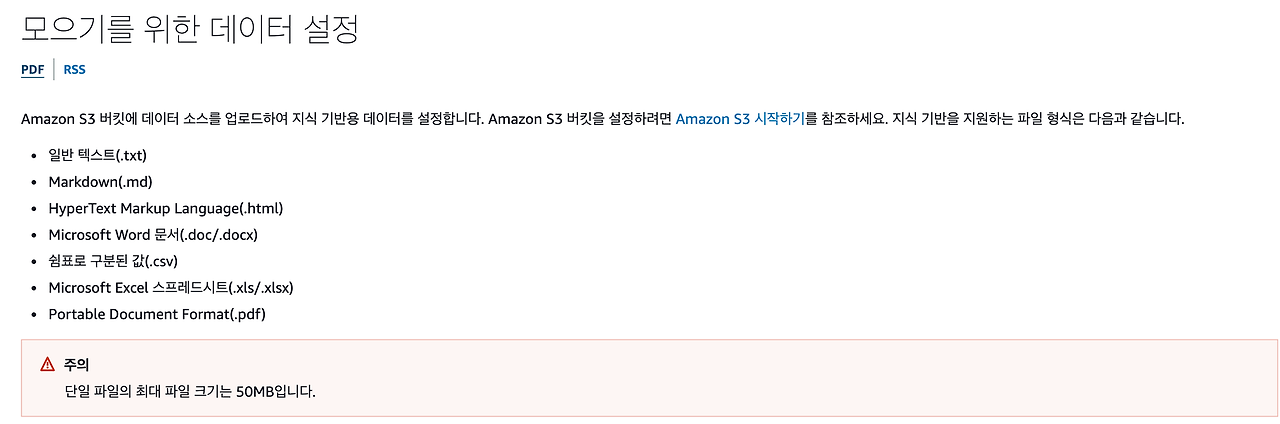
보통 형식된 데이터 설정이 제공되나, Ansible 는 스핑크스 기반의 Doc 웹사이트 혹은 py 확장자로 제공됩니다. 각 데이터 변환을 위한 과정은 다음과 같이 진행했습니다.
- rst → markdown 변환 (참고 블로그)
- py 확장자 → text 변환
변환한 데이터를 S3 에 업로드하고 Knowledge Base 구성하겠습니다.
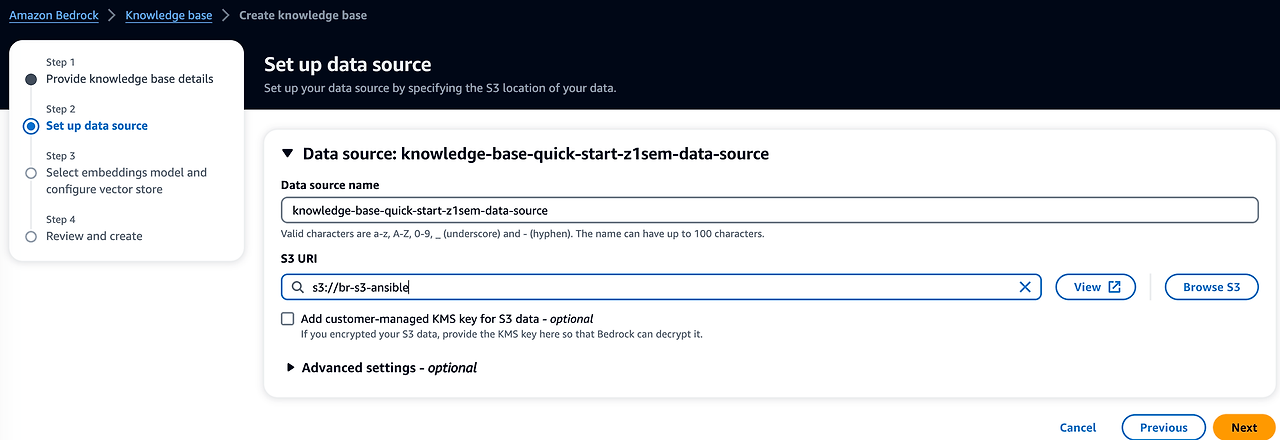
- 지식 기반 데이터 생성 저장소를 불러옵니다. 상단에 앤서블 자료들을 업로드한 s3를 설정해주세요.
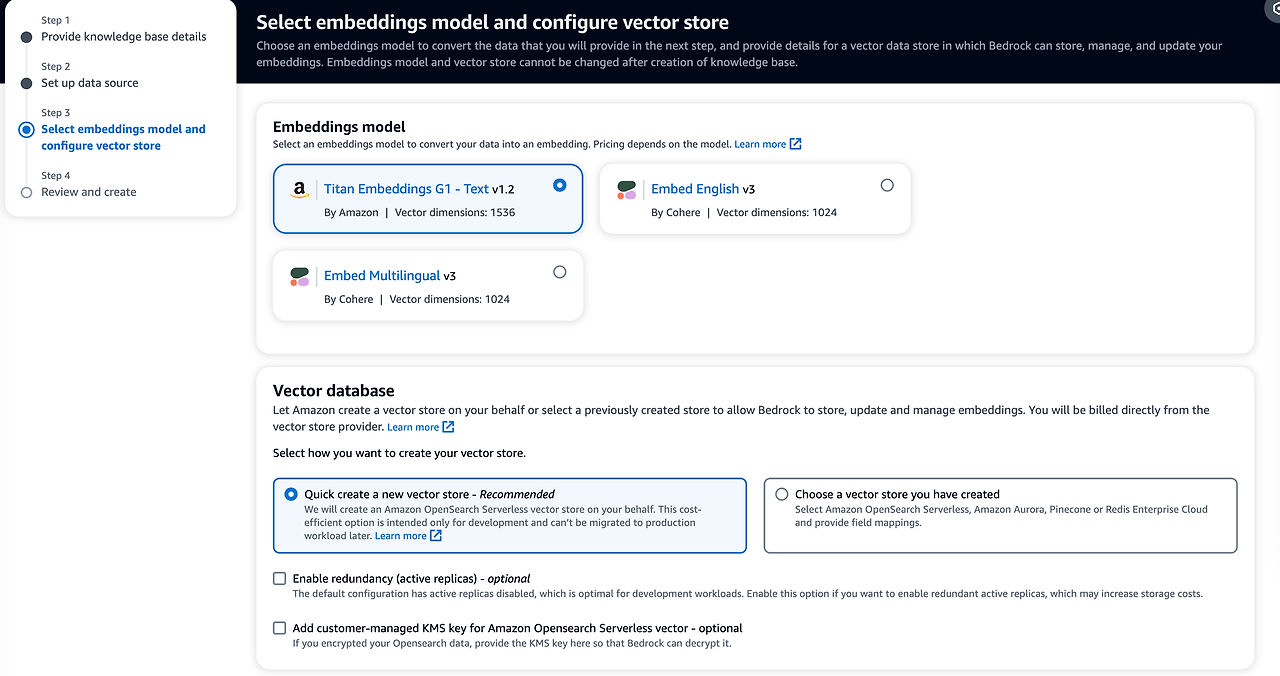
- 임베딩 모델과 벡터 데이터베이스를 설정합니다. 필자는 기본 모델과 데이터베이스(opensearch serverless)를 사용하여 구성하였습니다.
Knowledge Base 구성한 다음 지식 기반 데이터베이스 저장소(s3)를 벡터 데이터베이스(opensearch serverless)로 동기화가 필요합니다. 구성한다음 sync를 선택하면 자동으로 진행하시거나 Data Source 의 Sync를 통해 진행해주세요.


BedRock Agent 구성 및 테스트
Bedrock Agent 구성을 통해 앤서블GPT를 테스트해보겠습니다. Agent 구성을 위해 상단 react 항목의 Action Group, RAG 항목의 Knowledge Base 구성을 진행해주세요.
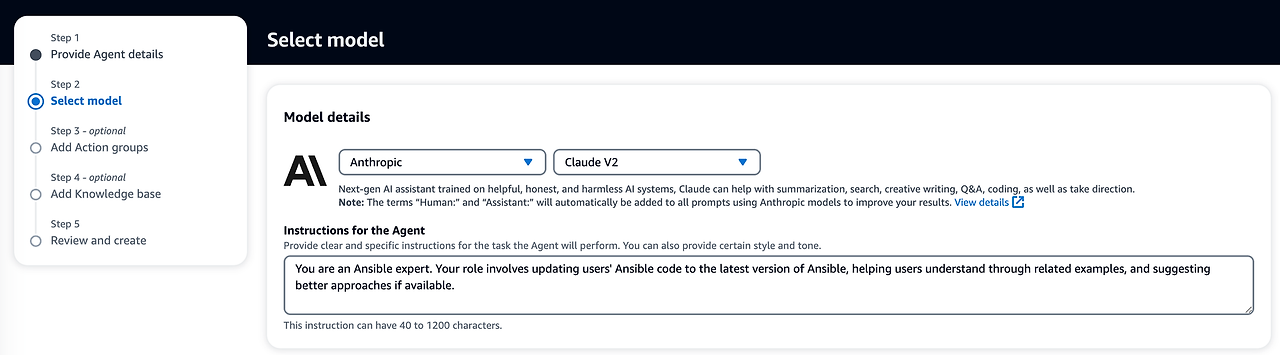
- Instructions for the Agent 에 실행 prompt을 작성합니다. 필자는 앤서블 전문가와 코드 수정을 사용자에게 가이드해달라고 작성했습니다.
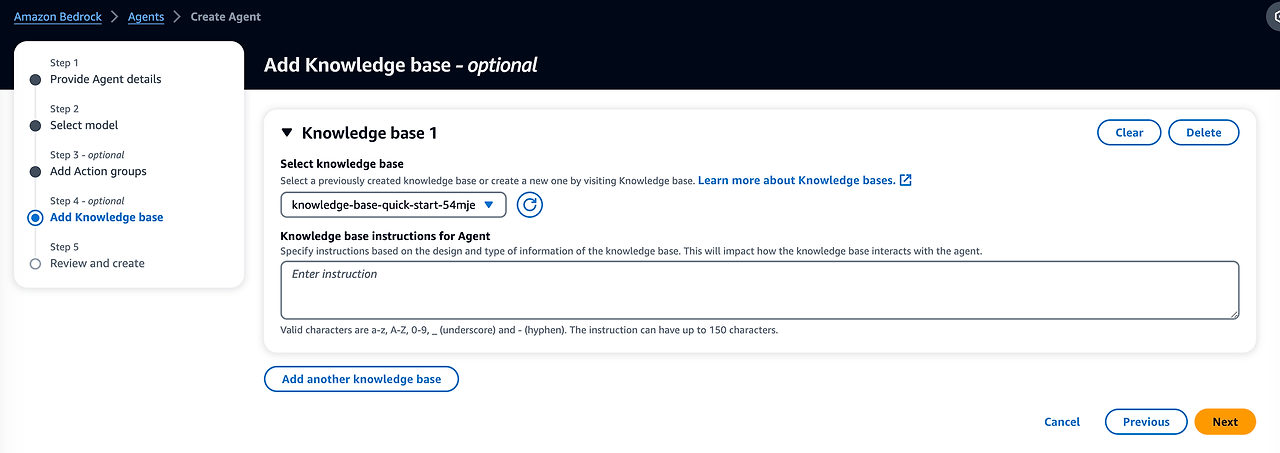
- knowledge base에서 실행 promt를 등록합니다. 필자는 해당 지식베이스가 최신 버전의 앤서블 가이드 문서이고, 해당 문서를 기준으로 사용자에게 가이드를 제공해달라고 작성했습니다.
Agent가 구성되면, 테스트 툴팁을 통해 테스트가 가능하나, Agent를 통해 입력값을 전달하면 이상한 값이 나오는 것을 확인할 수 있습니다. 이에 대한 원인으로는 정제되지 않은 데이터 전달과 정확하지 않은 action group 템플릿 전달이 있겠습니다.
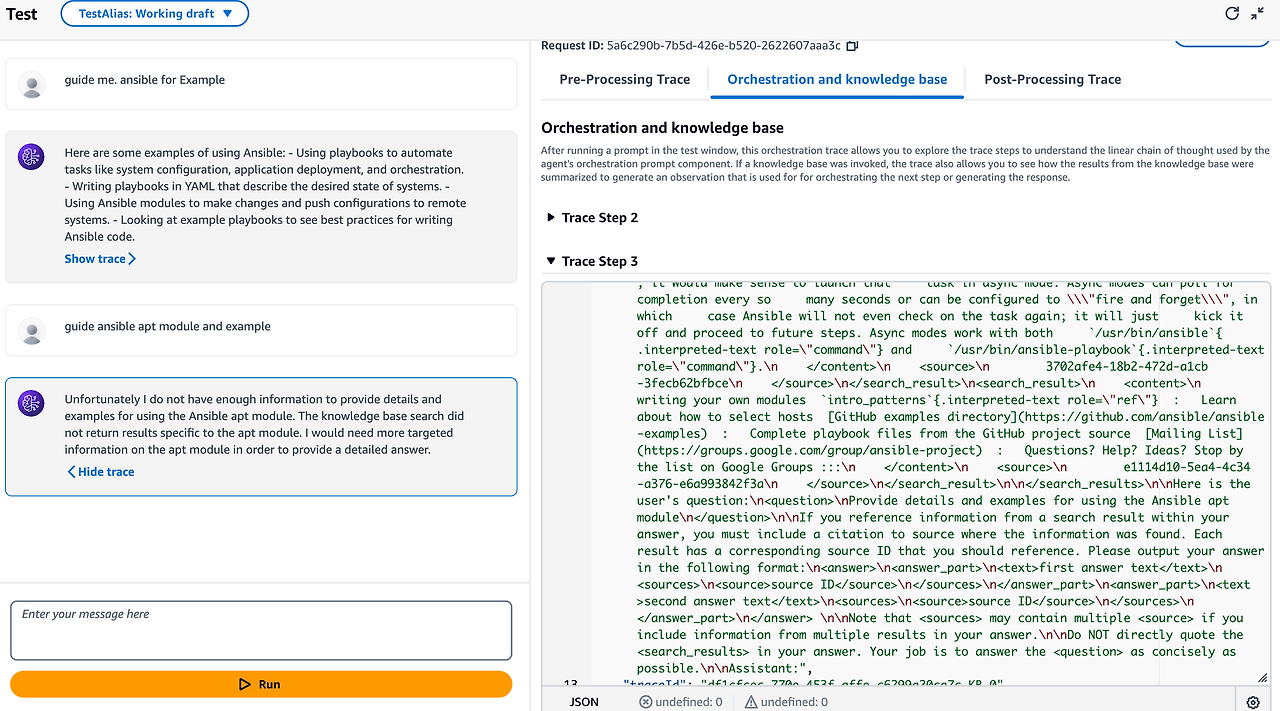
대체로 확인하기 위해 Agent 모델을 제외하고 Knowledge Base 에서 테스트를 진행하면 참고 문서와 함께 정삭적으로 출력되는 것을 알 수 있습니다. 다만, 줄 맞춤이 최적화되어 있지 않네요.
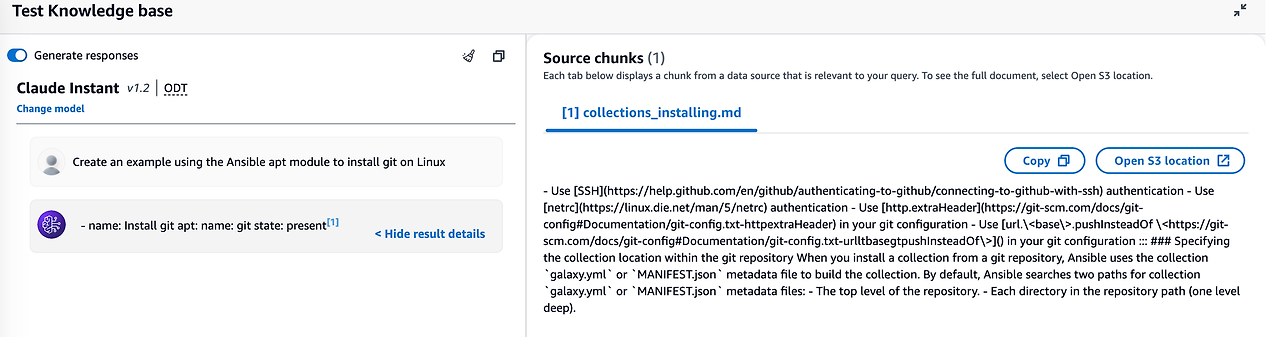
또, 아쉬운 점은 Knowledge Base 에서 코드를 전달하고 최신 버전의 코드 마이그레이션을 주문했지만, 결과는 좋지 않았습니다.
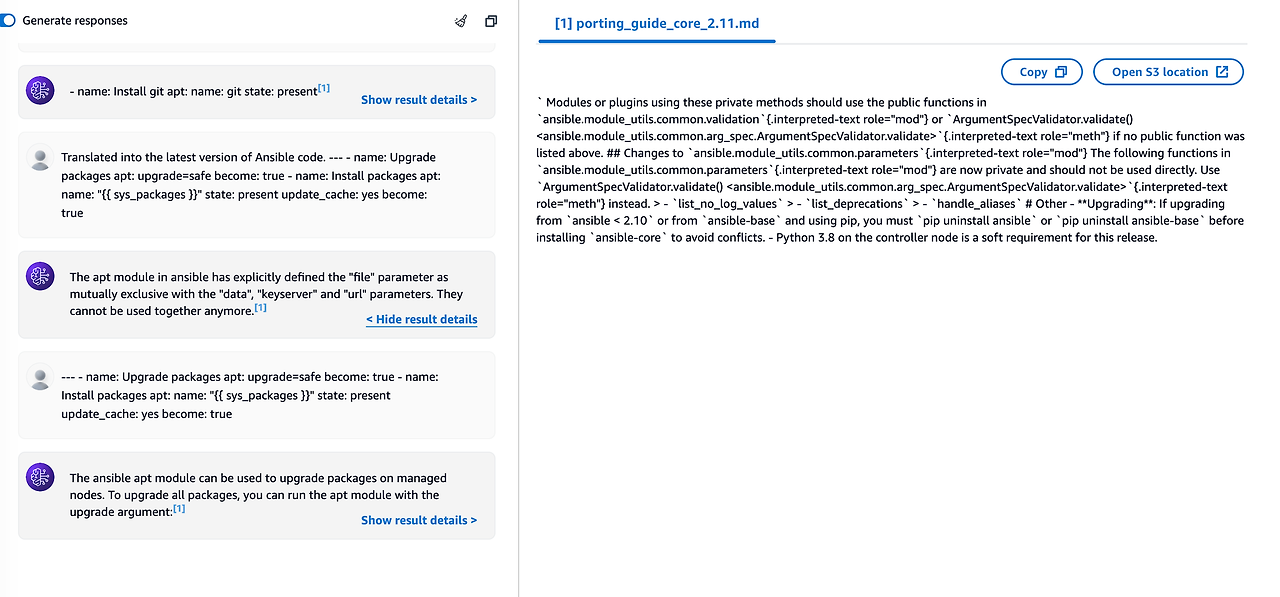
부족한 점을 보완해서 다음 모델을 만든다면 다음과 같이 정리할 수 있겠습니다.
- 정제된 데이터 수집(예제 기반의 데이터 전달)
- React Agent 템플릿과 람다 구성
부족하지만, LLM 기술을 맛볼 수 있었습니다. 결과 모델에 아쉽지만, 코드 제네제네이션 예제가 나오면 참고하여 다시 구성하고 싶네요.
리소스 삭제
리소스 삭제로 Bedrock, Knowledge Base, Agent, S3, Opensearch를 각 콘솔에서 지워야 합니다. 특히, opensearch 가 문제인데 bedrock에서 리소스를 삭제해도 Opensearch는 지워지지 않아 별도로 지워야 합니다.
'Cloud Tech' 카테고리의 다른 글
| Istio On EKS (0) | 2024.03.16 |
|---|---|
| Gitops Bridge를 통한 멀티클러스터 구성 자동화 (0) | 2024.03.09 |
| 오픈소스를 활용한 Amazon EKS 최적화 AMI 구성하기 (0) | 2024.02.04 |
| Ansible과 Packer를 활용한 Golden Image 구성 (0) | 2024.02.03 |
| 앤서블 기본 문법 이해하기 (0) | 2024.01.20 |