Build GenAI & ML for Performance and Scale, using Amazon EKS, Amazon FSx and AWS Inferentia 워크샵 내용을 정리합니다.
워크샵 제공해주신 AWS 관계자님 & CloudNET@ 가시다님 감사합니다.
워크샵에서는 EKS에서 LLM을 다루기 위한 AWS 서비스를 소개합니다.
- FSx for Lustre
- AWS Interentia

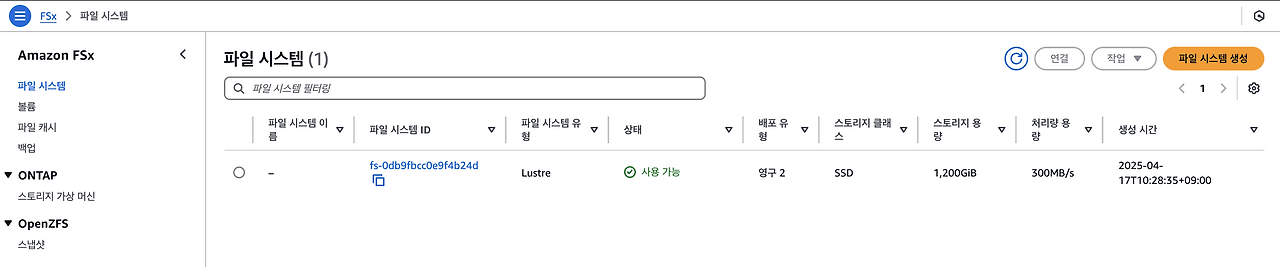
Amazon FSx for Lustre에 모델 데이터 호스팅
AI 모델(Mistral-7B-Instruct)을 Amazon S3에 저장하고, 이 데이터를 빠르게 사용할 수 있도록 Amazon FSx for Lustre 에 연결합니다. Kubernetes 기반의 Amazon EKS 클러스터는 이 파일 시스템에서 모델 데이터를 가져와 Generative AI 애플리케이션이 사용할 수 있게 합니다.
Amazon FSx for Lustre ?
Lustre용 Amazon FSx FSx for Lustre는 속도가 중요한 워크로드(예: 머신 러닝, 분석, 고성능 컴퓨팅)를 위한 고성능 병렬 파일 시스템을 제공하는 완전 관리형 서비스입니다.
- 매우 낮은 지연 시간(<1ms)
- 매우 높은 처리량(TB/s), 수백만의 IOPS 확장 지원
- 파일 시스템, 병렬 액세스 가능
- Amazon S3와의 통합으로, S3의 데이터를 고성능 파일 시스템으로 쉽게 연동
|
특징
|
의미
|
AI 운영 관점
|
|
낮은 지연시간(Low Latency)
|
데이터 접근 시 지연 시간이 밀리초 이하로 매우 짧음
|
AI 모델 로딩 시간 단축 → 서비스 시작 시간 단축 및 즉각적 응답 가능
|
|
높은 처리량(High Throughput)
|
초당 처리 가능한 데이터량(TB/s급)이 매우 많음
|
빠른 추론 속도 → 사용자에게 실시간 또는 근실시간 서비스 제공 가능
|
|
병렬 액세스 지원(Parallel Access)
|
여러 컨테이너가 동시에 모델 데이터 접근 가능
|
다수 사용자 동시 요청에도 성능 저하 없이 안정적 서비스 운영 가능
|
|
Amazon S3 자동 동기화(Automatic Sync with S3)
|
S3 버킷과 자동으로 데이터 동기화 및 최신화
|
AI 모델 업데이트·배포가 용이하여 관리 효율성 극대화
|
FSx for Lustre는 EKS에서 CSI Driver 통해 통합 관리가 가능합니다. (EBS, EFS, S3 처럼)
IRSA 설정을 위해 아래 IAM 정책과 서비스 계정을 생성합니다.
cat << EOF > fsx-csi-driver.json
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Action":[
"iam:CreateServiceLinkedRole",
"iam:AttachRolePolicy",
"iam:PutRolePolicy"
],
"Resource":"arn:aws:iam::*:role/aws-service-role/s3.data-source.lustre.fsx.amazonaws.com/*"
},
{
"Action":"iam:CreateServiceLinkedRole",
"Effect":"Allow",
"Resource":"*",
"Condition":{
"StringLike":{
"iam:AWSServiceName":[
"fsx.amazonaws.com"
]
}
}
},
{
"Effect":"Allow",
"Action":[
"s3:ListBucket",
"fsx:CreateFileSystem",
"fsx:DeleteFileSystem",
"fsx:DescribeFileSystems",
"fsx:TagResource"
],
"Resource":[
"*"
]
}
]
}
EOFaws iam create-policy \
--policy-name Amazon_FSx_Lustre_CSI_Driver \
--policy-document file://fsx-csi-driver.jsoneksctl create iamserviceaccount \
--region $AWS_REGION \
--name fsx-csi-controller-sa \
--namespace kube-system \
--cluster $CLUSTER_NAME \
--attach-policy-arn arn:aws:iam::$ACCOUNT_ID:policy/Amazon_FSx_Lustre_CSI_Driver \
--approve위 생성한 role_arn을 저장합니다.
저장한 role_arn은 Lustre FSx의 드라이버에 사용됩니다.
export ROLE_ARN=$(aws cloudformation describe-stacks --stack-name "eksctl-${CLUSTER_NAME}-addon-iamserviceaccount-kube-system-fsx-csi-controller-sa" --query "Stacks[0].Outputs[0].OutputValue" --region $AWS_REGION --output text)
echo $ROLE_ARN# fsx csi driver 설치
kubectl apply -k "github.com/kubernetes-sigs/aws-fsx-csi-driver/deploy/kubernetes/overlays/stable/?ref=release-1.2"
# annotate 설정
kubectl annotate serviceaccount -n kube-system fsx-csi-controller-sa \
eks.amazonaws.com/role-arn=$ROLE_ARN --overwrite=true
# 설정 확인
kubectl get sa/fsx-csi-controller-sa -n kube-system -o yaml
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::450...:role/eksctl-eksworkshop-addon-iamserviceacco설정이 끝났으면 FSx를 사용하겠습니다.
해당 워크샵에서는 정적 프로비저닝(이미 생성한 PV를 이용)을 통해 스토리지를 사용합니다.
- 정적 프로비저닝 : 관리자가 백엔드 스토리지 엔티티를 만들고 PV를 생성하며, 사용자는 이 PV가 자신의 Pod에서 사용되도록 클레임(PVC)을 만듭니다.
- 동적 프로비저닝 : 사용자가 PVC를 요청하면 CSI 드라이버가 사용자 요구 사항에 따라 PV(및 해당 백업 스토리지 엔티티)를 자동으로 생성합니다. 이 방법은 관리자가 미리 생성해야 하는 별도의 프로세스가 필요하지 않습니다.FSx는 이미 생성하였고, 메타데이터를 통해 쿠버네티스 볼륨 객체로 연결하겠습니다.
- 스토리지 클래스(SSD) 에 EFA 도 활성화 가능합니다.
# 스토리지 불러오기
FSXL_VOLUME_ID=$(aws fsx describe-file-systems --query 'FileSystems[].FileSystemId' --output text)
DNS_NAME=$(aws fsx describe-file-systems --query 'FileSystems[].DNSName' --output text)
MOUNT_NAME=$(aws fsx describe-file-systems --query 'FileSystems[].LustreConfiguration.MountName' --output text)
# 스토리지 값 교체
sed -i'' -e "s/FSXL_VOLUME_ID/$FSXL_VOLUME_ID/g" fsxL-persistent-volume.yaml
sed -i'' -e "s/DNS_NAME/$DNS_NAME/g" fsxL-persistent-volume.yaml
sed -i'' -e "s/MOUNT_NAME/$MOUNT_NAME/g" fsxL-persistent-volume.yaml
# 원본 데이터
# fsxL-persistent-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: fsx-pv
spec:
persistentVolumeReclaimPolicy: Retain
capacity:
storage: 1200Gi
volumeMode: Filesystem
accessModes:
- ReadWriteMany
mountOptions:
- flock
csi:
driver: fsx.csi.aws.com
volumeHandle: FSXL_VOLUME_ID
volumeAttributes:
dnsname: DNS_NAME
mountname: MOUNT_NAME
# 배포
kubectl apply -f fsxL-persistent-volume.yaml
# PV 확인
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
fsx-pv 1200Gi RWX Retain Available <unset> 37s
pvc-bdaca0e3-9a27-4f58-ae7f-4035769cf163 50Gi RWO Delete Bound kube-prometheus-stack/data-prometheus-kube-prometheus-stack-prometheus-0 gp3 <unset> 2d9h# PVC 배포
# fsxL-claim.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: fsx-lustre-claim
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
resources:
requests:
storage: 1200Gi
volumeName: fsx-pv # 생성한 볼륨 연결
# PVC 생성
kubectl apply -f fsxL-claim.yaml
# PV, PVC 확인
kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
persistentvolume/fsx-pv 1200Gi RWX Retain Bound default/fsx-lustre-claim <unset> 105s
persistentvolume/pvc-bdaca0e3-9a27-4f58-ae7f-4035769cf163 50Gi RWO Delete Bound kube-prometheus-stack/data-prometheus-kube-prometheus-stack-prometheus-0 gp3 <unset> 2d9h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
persistentvolumeclaim/fsx-lustre-claim Bound fsx-pv 1200Gi RWX <unset> 12sFSx 성능과 지표는 콘솔을 통해 확인이 가능합니다.

S3 연결은 데이터 리포지토리에서 설정이 가능합니다.

Deploy Generative AI Chat application
Amazon EKS 클러스터에 vLLM Pod와 WebUI Pod를 배포하여 Kubernetes에서 생성 AI 챗봇 애플리케이션을 구성하고 배포하겠습니다.
구성 환경 고려점으로 아래 사항을 다룹니다.
- Amazon FSx for Lustre와 Amazon S3를 사용하여 Mistral-7B 모델을 저장하고 액세스
- Karpenter를 사용하여 AWS inferentia2 EC2 노드(생성 AI를 위해 설계된 가속 컴퓨팅)를 구동하고, 컨테이너 이미지에서 vLLM Pod를 실행
AWS inferentia2 ?
AWS 인퍼렌시아 Amazon Web Services(AWS)에서 딥 러닝 및 생성적 AI 추론 애플리케이션을 가속화하도록 설계한 맞춤형 머신 러닝 칩입니다. AWS Inferentia 액셀러레이터는 TensorFlow, PyTorch, MXNet과 같은 널리 사용되는 머신 러닝 프레임워크를 지원하는 Amazon EC2에서 최저 비용으로 고성능을 제공합니다. Inferentia2 액셀러레이터는 머신 러닝 모델을 대규모로 배포하도록 특별히 최적화되어 있으며, 딥 러닝 모델을 대규모로 실행하도록 특별히 설계되었습니다. AWS Inferentia2 기반 Amazon EC2 Inf2 인스턴스는 대규모 언어 모델(LLM) 및 잠재 확산 모델과 같이 점점 더 복잡해지는 모델을 배포하도록 최적화되어 있습니다.
AWS Inferentia는 머신 러닝의 추론 단계를 가속화하는 데 사용됩니다. 추론은 훈련된 모델을 사용하여 새로운 데이터를 기반으로 예측이나 결정을 내리는 것을 포함합니다. 이 단계는 낮은 지연 시간과 높은 처리량이 필요한 실시간 애플리케이션 및 서비스에 매우 중요합니다. AWS Inferentia2는 다양한 추론 워크로드에 높은 처리량과 낮은 지연 시간을 제공하도록 설계되었습니다. 각 Inferentia2 가속기에는 2세대 NeuronCore 2개가 있으며, EC2 Inf2 인스턴스당 최대 12개의 Inferentia2 가속기를 사용할 수 있습니다. 각 Inferentia2 가속기는 최대 190TFLOPS(초당 테라 부동 소수점 연산)의 FP16 성능을 지원합니다. Inferentia2는 가속기당 32GB의 HBM을 제공하여 Inferentia1보다 총 메모리 용량이 4배, 메모리 대역폭이 10배 증가합니다.
AWS Neuron SDK ?
AWS 뉴런 SDK 고성능의 비용 효율적인 딥 러닝(DL) 가속을 지원하는 컴파일러, 런타임 및 프로파일링 도구를 갖춘 SDK입니다. AWS Neuron SDK는 PyTorch 및 TensorFlow와 같은 널리 사용되는 ML 프레임워크와 기본적으로 통합됩니다. AWS Neuron을 사용하면 이러한 프레임워크를 사용하여 AWS Inferentia 가속기 모두에 DL 모델을 최적으로 배포할 수 있으며, Neuron은 코드 변경을 최소화하고 공급업체별 솔루션과의 연계를 최소화하도록 설계되었습니다. Neuron은 Inferentia 가속기에서 자연어 처리(NLP)/이해, 언어 번역, 텍스트 요약, 비디오 및 이미지 생성, 음성 인식, 개인화, 사기 탐지 등을 위한 추론 애플리케이션을 실행할 수 있도록 지원합니다.
Inferentia 칩은 인스턴스 inf2 타입을 통해 설정됩니다.
Karpenter 구성을 통해 Inferentia 노드를 배포하겠습니다.
- aws.amazon.com/neuron 가 있어야 노드 생성
- 노드는 inf2 타입이며 Spot & OnDemand 를 통해 구성
cat inferentia_nodepool.yaml
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: inferentia
labels:
intent: genai-apps
NodeGroupType: inf2-neuron-karpenter
spec:
template:
spec:
taints:
- key: aws.amazon.com/neuron
value: "true"
effect: "NoSchedule"
requirements:
- key: "karpenter.k8s.aws/instance-family"
operator: In
values: ["inf2"]
- key: "karpenter.k8s.aws/instance-size"
operator: In
values: [ "xlarge", "2xlarge", "8xlarge", "24xlarge", "48xlarge"]
- key: "kubernetes.io/arch"
operator: In
values: ["amd64"]
- key: "karpenter.sh/capacity-type"
operator: In
values: ["spot", "on-demand"]
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: inferentia
limits:
cpu: 1000
memory: 1000Gi
disruption:
consolidationPolicy: WhenEmpty
# expireAfter: 720h # 30 * 24h = 720h
consolidateAfter: 180s
weight: 100
---
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: inferentia
spec:
amiFamily: AL2
amiSelectorTerms:
- alias: al2@v20240917
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
deleteOnTermination: true
volumeSize: 100Gi
volumeType: gp3
role: "Karpenter-eksworkshop"
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "eksworkshop"
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "eksworkshop"
tags:
intent: apps
managed-by: karpenter
# 배포
kubectl apply -f inferentia_nodepool.yaml
# 구성 확인
kubectl get nodepool,ec2nodeclass inferentia
NAME NODECLASS NODES READY AGE
nodepool.karpenter.sh/inferentia inferentia 0 True 24s
NAME READY AGE
ec2nodeclass.karpenter.k8s.aws/inferentia True 24s노드 구성이 끝났다면 Neuron Device Plugin과 Neuron Scheduler를 설치해야 합니다.
# 플러그인 설치
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/k8s-neuron-device-plugin-rbac.yml
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/k8s-neuron-device-plugin.yml
# 스케쥴러 배포
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/k8s-neuron-scheduler-eks.yml
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/my-scheduler.yml 구성이 끝났다면 LLM 모델을 배포하겠습니다. LLM 모델 구성을 확인하면 vllm 이미지를 생성하고 모델은 FSx 스토리지에서 가져오는 것을 확인할 수 있습니다.
Q. vllm ?
LLM 추론 및 제공을 위한 오픈 소스의 사용하기 쉬운 라이브러리입니다. Mistral-7B-Instruct와 같은 LLM 모델을 배포하여 텍스트 생성 추론을 제공할 수 있는 프레임워크를 제공합니다. vLLM은 OpenAI API와 호환되는 API를 제공하여 LLM 애플리케이션을 쉽게 통합할 수 있도록 합니다.
vLLM은 다음과 같은 점에서 빠릅니다.
- 최첨단 서비스 처리량
- PagedAttention을 이용한 주의 키 및 값 메모리의 효율적인 관리
- 들어오는 요청의 지속적인 배치
- CUDA/HIP 그래프를 통한 빠른 모델 실행
vLLM은 다음과 함께 사용하기 쉽고 유연합니다.
- 인기 있는 HuggingFace 모델과의 원활한 통합
- OpenAI 호환 API 서버
- 접두사 캐싱 지원
- AWS Neuron, NVIDIA GPU 및 기타 칩셋을 지원합니다.
cat mistral-fsxl.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-mistral-inf2-deployment
spec:
replicas: 1
selector:
matchLabels:
app: vllm-mistral-inf2-server
template:
metadata:
labels:
app: vllm-mistral-inf2-server
spec:
tolerations:
- key: "aws.amazon.com/neuron"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: inference-server
image: public.ecr.aws/u3r1l1j7/eks-genai:neuronrayvllm-100G-root
resources:
requests:
aws.amazon.com/neuron: 1
limits:
aws.amazon.com/neuron: 1
args:
- --model=$(MODEL_ID)
- --enforce-eager
- --gpu-memory-utilization=0.96
- --device=neuron
- --max-num-seqs=4
- --tensor-parallel-size=2
- --max-model-len=10240
- --served-model-name=mistralai/Mistral-7B-Instruct-v0.2-neuron
env:
- name: MODEL_ID
value: /work-dir/Mistral-7B-Instruct-v0.2/
- name: NEURON_COMPILE_CACHE_URL
value: /work-dir/Mistral-7B-Instruct-v0.2/neuron-cache/
- name: PORT
value: "8000"
volumeMounts:
- name: persistent-storage
mountPath: "/work-dir"
volumes:
- name: persistent-storage
persistentVolumeClaim:
claimName: fsx-lustre-claim
---
apiVersion: v1
kind: Service
metadata:
name: vllm-mistral7b-service
spec:
selector:
app: vllm-mistral-inf2-server
ports:
- protocol: TCP
port: 80
targetPort: 8000
모델과 상호작용하기 위한 WebUI 채팅 애플리케이션 배포
이 애플리케이션은 워크숍에서 배포할 vLLM 호스팅 Mistral-7B-Instruct 모델에서 제공하는 OpenAI 호환 엔드포인트를 사용하도록 설계되었습니다. Open WebUI 애플리케이션을 사용하면 사용자가 채팅 기반 인터페이스를 통해 LLM 모델과 상호 작용할 수 있습니다.
애플리케이션을 배포하고 인그래스 URL을 통해 채팅 애플리케이션을 확인하겠습니다
cat open-webui.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: open-webui-deployment
spec:
replicas: 1
selector:
matchLabels:
app: open-webui-server
template:
metadata:
labels:
app: open-webui-server
spec:
containers:
- name: open-webui
image: kopi/openwebui
env:
- name: WEBUI_AUTH
value: "False"
- name: OPENAI_API_KEY
value: "xxx"
- name: OPENAI_API_BASE_URL
value: "http://vllm-mistral7b-service/v1"
---
apiVersion: v1
kind: Service
metadata:
name: open-webui-service
annotations:
service.beta.kubernetes.io/aws-load-balancer-type: external
service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: instance
spec:
selector:
app: open-webui-server
# type: LoadBalancer
ports:
- protocol: TCP
port: 80
targetPort: 8080
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: open-webui-ingress
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/healthcheck-path: /
alb.ingress.kubernetes.io/healthcheck-interval-seconds: '10'
alb.ingress.kubernetes.io/healthcheck-timeout-seconds: '9'
alb.ingress.kubernetes.io/healthy-threshold-count: '2'
alb.ingress.kubernetes.io/unhealthy-threshold-count: '10'
alb.ingress.kubernetes.io/success-codes: '200-302'
alb.ingress.kubernetes.io/load-balancer-name: open-webui-ingress
labels:
app: open-webui-ingress
spec:
ingressClassName: alb
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: open-webui-service
port:
number: 80# 애플리케이션 배포
kubectl apply -f open-webui.yaml
# 인그래스 확인
kubectl get ing
NAME CLASS HOSTS ADDRESS PORTS AGE
open-webui-ingress alb * open-webui-ingress-2084735319.us-west-2.elb.amazonaws.com 80 17m오.. ChatGPT와 UI가 동일합니다

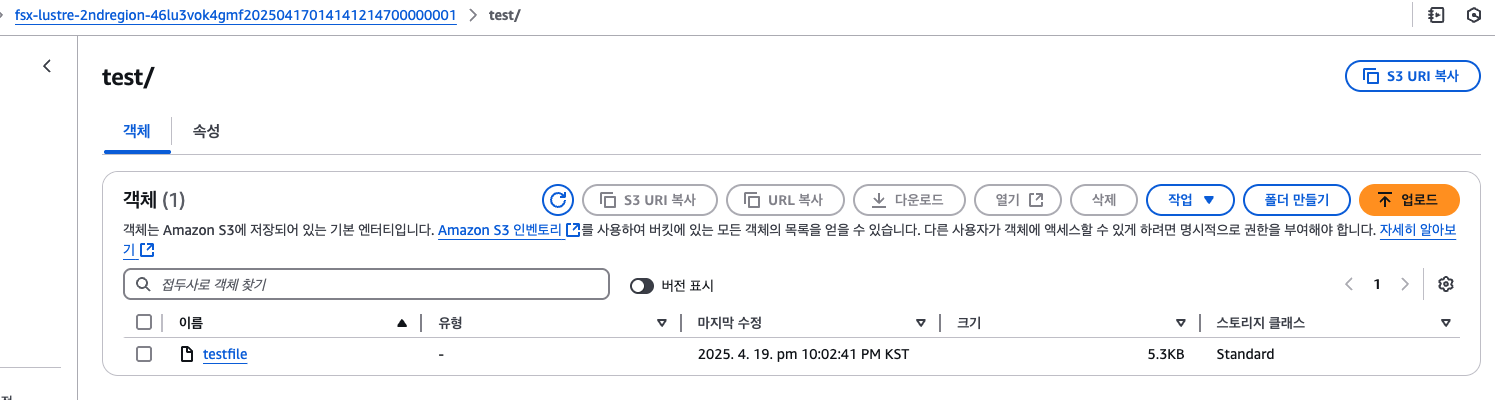
S3 크로스리전 복제 구성하기
FSx for Lustre가 지원하는 영구 볼륨의 EKS 포드에서 테스트 파일을 생성하고, 이 파일이 자동으로 S3 버킷으로 내보내지는 것을 확인하고, 구성할 S3 복제를 통해 해당 테스트 파일이 사용자를 위해 생성한 다른 대상 AWS 리전(us-east-2)의 S3 버킷에도 자동으로 복제하는 것을 확인하겠습니다.

S3 복제는 관리에서 설정이 가능합니다.

복제 규칙은 다음과 같이 설정하였습니다.
- 소스 버킷 범위를 접두사 test 로 지정
- 대상 버킷을 2ndregion 의 버킷으로 설정
- IAM 역할, 아래 참고

s3-cross-region-replication-role
{
"Statement": [
{
"Action": [
"s3:GetReplicationConfiguration",
"s3:ListBucket"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::fsx-lustre-46lu3vok4gmf20250417012432588100000001"
]
},
{
"Action": [
"s3:GetObjectVersion",
"s3:GetObjectVersionAcl",
"s3:GetObjectVersionForReplication",
"s3:GetObjectVersionTagging"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::fsx-lustre-46lu3vok4gmf20250417012432588100000001/*"
]
},
{
"Action": [
"s3:ReplicateObject",
"s3:ReplicateDelete",
"s3:ReplicateTags"
],
"Effect": "Allow",
"Resource": "arn:aws:s3:::fsx-lustre-2ndregion-46lu3vok4gmf20250417014141214700000001/*"
}
],
"Version": "2012-10-17"
}기능 확인을 위해 Mistral-7B 모델 파드에서 공유 및 복제할 테스트 파일을 생성하여 테스트하겠습니다.
모델 파드에서 testfile을 생성하고, 2dnregion-s3 에서 객체를 확인하겠습니다.
kubectl get pods
NAME READY STATUS RESTARTS AGE
kube-ops-view-5d9d967b77-q6frk 1/1 Running 0 2d11h
open-webui-deployment-5d7ff94bc9-zc76l 1/1 Running 0 54m
vllm-mistral-inf2-deployment-7d886c8cc8-tvbqh 1/1 Running 0 60m
kubectl exec -it vllm-mistral-inf2-deployment-7d886c8cc8-tvbqh -- bash
# FSx for Lustre 파일 시스템 자원 확인
df -h
Filesystem Size Used Avail Use% Mounted on
overlay 100G 23G 78G 23% /
tmpfs 64M 0 64M 0% /dev
tmpfs 7.7G 0 7.7G 0% /sys/fs/cgroup
10.0.36.134@tcp:/hqzdbb4v 1.2T 28G 1.1T 3% /work-dir # FSx for Lustre 파일 시스템
/dev/nvme0n1p1 100G 23G 78G 23% /etc/hosts
shm 64M 0 64M 0% /dev/shm
tmpfs 15G 12K 15G 1% /run/secrets/kubernetes.io/serviceaccount
tmpfs 7.7G 0 7.7G 0% /proc/acpi
tmpfs 7.7G 0 7.7G 0% /sys/firmware
# 경로 확인
cd /work-dir/
ls -ll
drwxr-xr-x 5 root root 33280 Apr 16 18:50 Mistral-7B-Instruct-v0.2
-rw-r--r-- 1 root root 151505 Apr 16 18:52 sysprep
#
cd /work-dir
mkdir test
cd test
cp /work-dir/Mistral-7B-Instruct-v0.2/README.md /work-dir/test/testfile
ls -ll /work-dir/test
번외(1) FSx 스토리지 성능 검사
CSI 드라이버가 프로비저닝하는 FSx for Lustre 파일 시스템의 스토리지 성능, IOPS, 처리량 및 지연 시간과 관련된 중요한 매개변수를 확인겠습니다.
도구, IOping 를 통해 실시간으로 I/O 지연 시간을 모니터링하고 배포할 EKS Pod에서 FSx for Lustre 드라이브의 성능을 테스트하겠습니다.
Nginx 파드(FSX 스토리지에 연결된) 를 배포하고 그 안에서 IOPing을 통해 성능을 검사합니다.
FSx 스토리지는 동적프로비저닝된 볼륨을 배포하고 사용합니다.
이를 위해 스토리지 클래스를 생성하겠습니다.
# FSx 스토리지 설정
VPC_ID=$(aws eks describe-cluster --name $CLUSTER_NAME --region $AWS_REGION --query "cluster.resourcesVpcConfig.vpcId" --output text)
SUBNET_ID=$(aws eks describe-cluster --name $CLUSTER_NAME --region $AWS_REGION --query "cluster.resourcesVpcConfig.subnetIds[0]" --output text)
SECURITY_GROUP_ID=$(aws ec2 describe-security-groups --filters Name=vpc-id,Values=${VPC_ID} Name=group-name,Values="FSxLSecurityGroup01" --query "SecurityGroups[*].GroupId" --output text)
# fsxL-storage-class.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: fsx-lustre-sc
provisioner: fsx.csi.aws.com
parameters:
subnetId: SUBNET_ID
securityGroupIds: SECURITY_GROUP_ID
deploymentType: SCRATCH_2
fileSystemTypeVersion: "2.15"
mountOptions:
- flock
sed -i'' -e "s/SUBNET_ID/$SUBNET_ID/g" fsxL-storage-class.yaml
sed -i'' -e "s/SECURITY_GROUP_ID/$SECURITY_GROUP_ID/g" fsxL-storage-class.yaml
# 볼륨 배포
kubectl apply -f fsxL-storage-class.yaml
# PVC 생성
cat fsxL-dynamic-claim.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: fsx-lustre-dynamic-claim
spec:
accessModes:
- ReadWriteMany
storageClassName: fsx-lustre-sc
resources:
requests:
storage: 1200Gi
# PVC 배포
kubectl apply -f fsxL-dynamic-claim.yaml
# 위 가용영역을 topology.kubernetes.io/zone 에 입력
cat pod_performance.yaml
kind: Pod
apiVersion: v1
metadata:
name: fsxl-performance
spec:
containers:
- name: fsxl-performance
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- name: persistent-storage
mountPath: /data
volumes:
- name: persistent-storage
persistentVolumeClaim:
claimName: fsx-lustre-dynamic-claim
tolerations:
- key: "aws.amazon.com/neuron"
operator: "Equal"
value: "true"
effect: "NoSchedule"동적 볼륨을 마운트하는데 있어 시간이 약 5~10분 소요됩니다.
kubectl exec -it fsxl-performance -- bash
apt-get update
apt-get install fio ioping -y
ioping -c 20 . 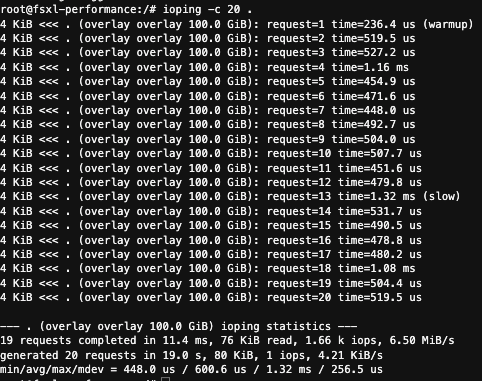
- 평균 600.6 μs 지연속도입니다.
FIO 명령을 실행하여 부하 테스트를 수행합니다.
FIO 테스트에서는 소규모 EKS 컨테이너 환경에서 50% 읽기/쓰기 혼합 비율과 8개의 동시 작업을 사용하는 무작위 읽기/쓰기 패턴을 사용하여 처리량 테스트를 위해 1MB의 큰 블록 크기(IOPS 테스트용 작은 블록 크기 대신)를 사용하는 부하 테스트 시뮬레이션을 실행
mkdir -p /data/performance
cd /data/performance
fio --randrepeat=1 --ioengine=libaio --direct=1 --gtod_reduce=1 --name=fiotest --filename=testfio8gb --bs=1MB --iodepth=64 --size=8G --readwrite=randrw --rwmixread=50 --numjobs=8 --group_reporting --runtime=10
...
--- . (overlay overlay 100.0 GiB) ioping statistics ---
19 requests completed in 11.4 ms, 76 KiB read, 1.66 k iops, 6.50 MiB/s
generated 20 requests in 19.0 s, 80 KiB, 1 iops, 4.21 KiB/s
min/avg/max/mdev = 448.0 us / 600.6 us / 1.32 ms / 256.5 us
root@fsxl-performance:/# mkdir -p /data/performance
root@fsxl-performance:/# cd /data/performance
root@fsxl-performance:/data/performance# fio --randrepeat=1 --ioengine=libaio --direct=1 --gtod_reduce=1 --name=fiotest --filename=testfio8gb --bs=1MB --iodepth=64 --size=8G --readwrite=randrw --rwmixread=50 --numjobs=8 --group_reporting --runtime=10
fiotest: (g=0): rw=randrw, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=libaio, iodepth=64
...
fio-3.33
Starting 8 processes
fiotest: Laying out IO file (1 file / 8192MiB)
Jobs: 8 (f=8): [m(8)][4.2%][r=146MiB/s,w=163MiB/s][r=146,w=163 IOPS][eta 04m:13s]
fiotest: (groupid=0, jobs=8): err= 0: pid=727: Sat Apr 19 14:08:21 2025
read: IOPS=182, BW=182MiB/s (191MB/s)(2003MiB/10979msec)
bw ( KiB/s): min=95880, max=425984, per=100.00%, avg=195627.20, stdev=12508.18, samples=139
iops : min= 92, max= 416, avg=190.89, stdev=12.23, samples=139
write: IOPS=189, BW=189MiB/s (198MB/s)(2077MiB/10979msec); 0 zone resets
bw ( KiB/s): min=98304, max=512000, per=100.00%, avg=200030.37, stdev=13871.03, samples=139
iops : min= 96, max= 500, avg=195.21, stdev=13.54, samples=139
cpu : usr=0.09%, sys=8.76%, ctx=9803, majf=0, minf=52
IO depths : 1=0.2%, 2=0.4%, 4=0.8%, 8=1.6%, 16=3.1%, 32=6.3%, >=64=87.6%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=99.8%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.2%, >=64=0.0%
issued rwts: total=2003,2077,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=64
Run status group 0 (all jobs):
READ: bw=182MiB/s (191MB/s), 182MiB/s-182MiB/s (191MB/s-191MB/s), io=2003MiB (2100MB), run=10979-10979msec
WRITE: bw=189MiB/s (198MB/s), 189MiB/s-189MiB/s (198MB/s-198MB/s), io=2077MiB (2178MB), run=10979-10979msec- MiB 블록 접근 성능 기준으로 약 190MB/s 수준
번외(2) 멀티 GPU를 위한 AI/ML 인프라
단일 GPU로 학습 불가한 초대형 모델 시대 도래하였습니다.
- GPT-3: 1,750억 파라미터
- MT-NLG: 5,300억, PaLM: 5,400억
멀티 GPU로 AI/ML 인프라를 구성해야하는 것을 필수이지만, 네트워크 병목 현상이 존재합니다.
분산 학습에서 이루어지는 패턴 - AllReduce, AllGather, ReduceScatter 등

이러한 병목 현상에 따라 발생하는 이슈 예시는 다음과 같습니다.
- 8개 GPU 노드 간 AllReduce 작업에서 최대 70%의 시간이 통신에 소비
- GPU 활용률 저하 (60-70% 수준)
- 학습 시간 증가 (최대 2-3배)
네트워크 병목 현상을 해결하기 위해 AWS에서는 EFA (Elastic Fabric Adapter) 기술를 발표하였습니다.
EFA : GPU 네트워크 병목 문제를 해결하기 위해 설계된 혁신적인 네트워크 인터페이스
- OS 바이패스: 커널 우회 → 시스템 콜, 컨텍스트 스위칭, 인터럽트 최소화
- RDMA: CPU 개입 없이 원격 메모리에 직접 접근 → 제로카피 전송
- NCCL 통합: GPU 간 직접 통신 최적화 + 토폴로지 인식 + 자동 튜닝 지원

EFA 리전, 인스턴스 타입에 따라 지원됩니다.
aws를 통해 리전별 명령어를 통해 지원가능한 인스턴스를 확인하세요. (공식문서 참고)
aws ec2 describe-instance-types --region us-east-1 --filters Name=network-info.efa-supported,Values=true --query "InstanceTypes[*].[InstanceType]" --output text | sort
c5n.18xlarge
c5n.9xlarge
c5n.metal
c6a.48xlarge
c6a.metal
c6gn.16xlarge
c6i.32xlarge
...- g6.8xlarge 이상의 스펙에서만 지원됩니다.
Amazon EKS에 EFA를 통합함으로써 얻을 수 있는 주요 이점은 다음과 같습니다.
- 인프라 관리 간소화
- 비용 최적화
- 성능 최적화
- 개발자 경험 개선
EFA 동작 확인 (가이드)
필자는 비용 문제로 실습 내용으로 대체합니다.
# 예제 테라폼 clone
git clone https://github.com/aws-ia/terraform-aws-eks-blueprints.git
cd terraform-aws-eks-blueprints/patterns/nvidia-gpu-efa
# 인스턴스 타입 변경
sed -i "s/p5.48xlarge/g6e.8xlarge/g" eks.tf
# 테라폼 환경 구성
terraform init
terraform apply -target="module.vpc" -auto-approve
terraform apply -target="module.eks" -auto-approve
terraform apply -auto-approve
# efa 플러그인 및 테스트 파드 배포
./generate-efa-info-test.sh
sed -i "s/GPU_PER_WORKER=8/GPU_PER_WORKER=1/g" generate-efa-info-test.sh
sed -i "s/EFA_PER_WORKER=32/EFA_PER_WORKER=1/g" generate-efa-info-test.sh
# 로그 확인
kubectl logs -f $(kubectl get pods | grep launcher | cut -d ' ' -f 1)
Warning: Permanently added 'efa-info-test-worker-0.efa-info-test.default.svc' (ED25519) to the list of known hosts.
Warning: Permanently added 'efa-info-test-worker-1.efa-info-test.default.svc' (ED25519) to the list of known hosts.
[1,1]:provider: efa # 구성 확인
[1,1]: fabric: efa'AI' 카테고리의 다른 글
| AIOPs를 통한 업무 자동화 PoC(Holmesgpt를 곁들인..) (0) | 2025.03.29 |
|---|---|
| AWS Bedrock(LLM)을 활용한 앤서블 GPT 모델 만들기 (1) | 2024.02.11 |