Overview
EKS 서비스 워크로드 운영 안정성을 높이기 위해 본 글에서 아래 항목을 테스트하겠습니다.
- 서비스 무중단을 위한 애플리케이션 파드 내 ReadinessGate, preStop 설정 후 Downtime Zero 확인
Serivce Downtime Zero 구성
EKS 를 비롯한 쿠버네티스에서 롤링 업데이트 또는 노드 변경에 따라 파드 재기동을 자주 발생합니다.
일반적으로 파드가 이중화되고 파드를 하나씩 롤링업데이트하면 서비스 이상이 없을 것으로 예상하지만,,
Cloudwatch를 비롯한 대시보드 확인시 ELB 5XX가 일부 확인됩니다.
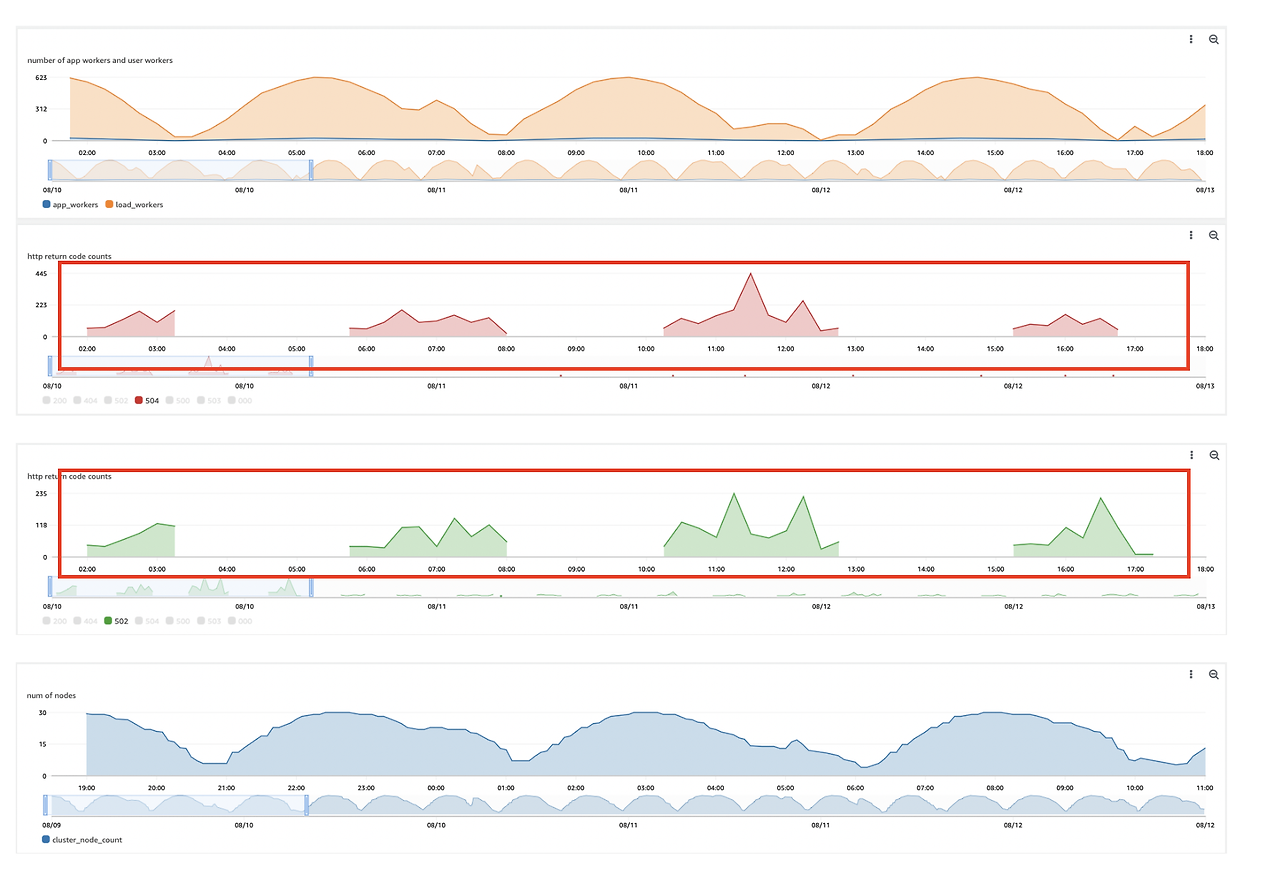
이는 AWS 타겟 그룹에서 파드 등록 및 삭제 과정에서 발생합니다.
AWS 로드밸런서 컨트롤러는 타켓 그룹에 새 파드를 등록하고, 기존 파드를 동시에 제거합니다.
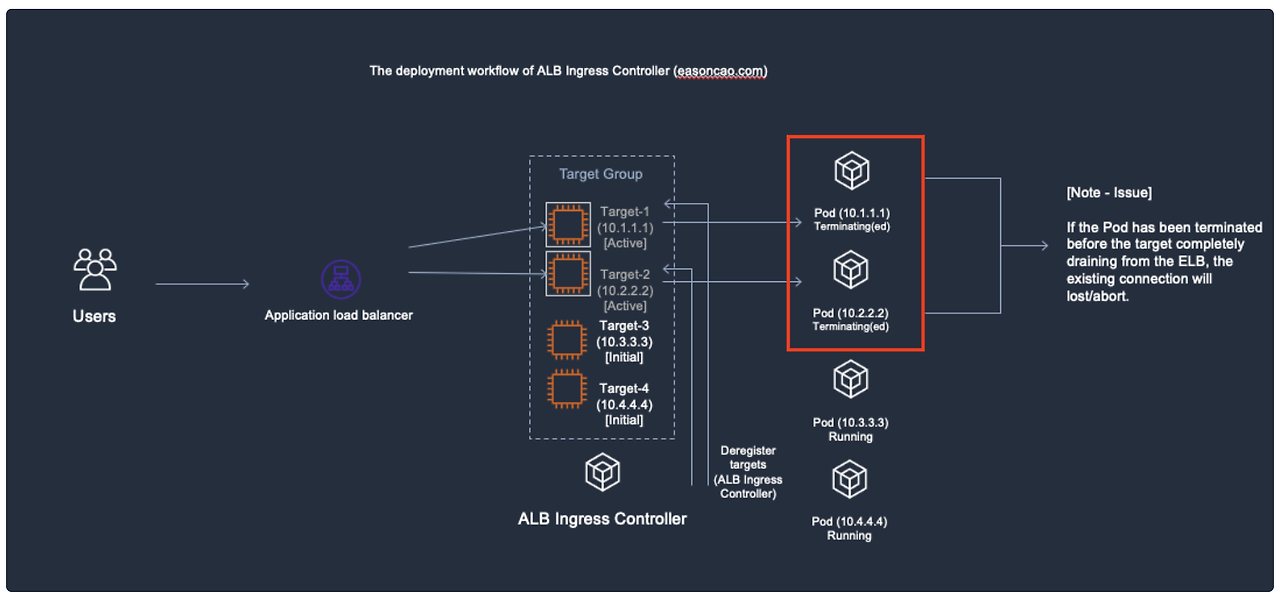
대상 그룹으로 연결하는 중 다음의 2가지 경우에 5XX 에러 코드가 반환됩니다.
- 기존 파드가 삭제되었지만, 타겟 그룹이 Active 상태로 트래픽이 삭제된 파드로 전달된 경우
- 기존 타켓 그룹이 Draining 된 상태이며 새로운 타겟 그룹이 헬스체크로 대기 중일 경우
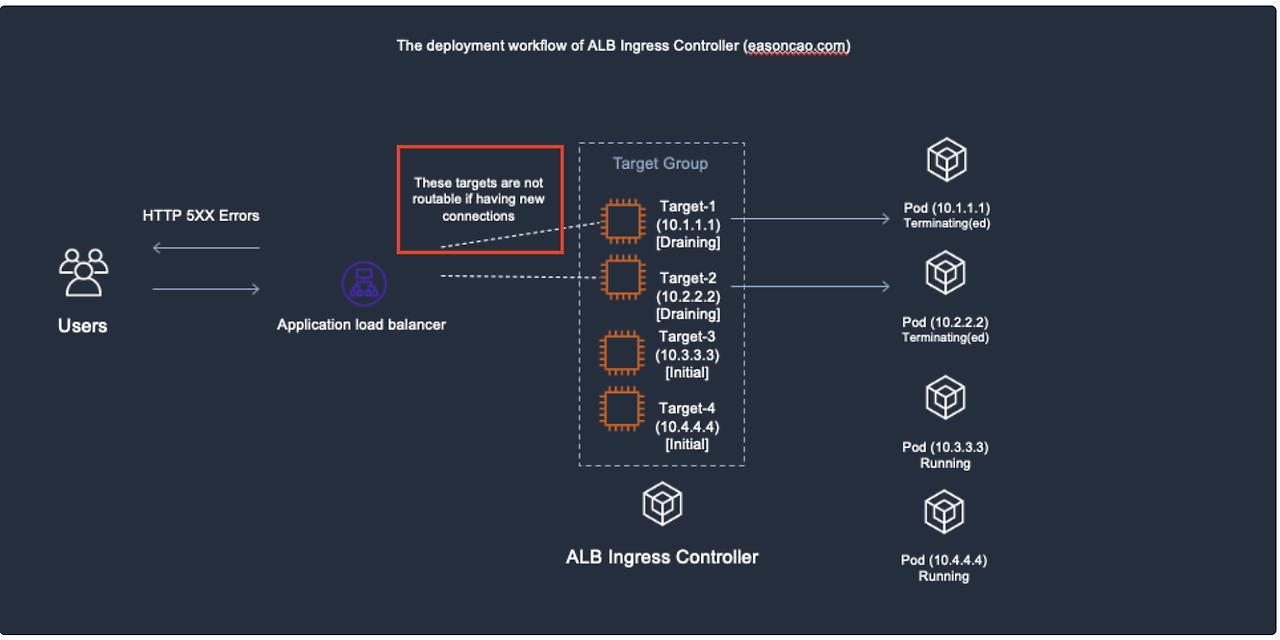
이를 최소화하기 위해서는 파드 라이프사이클 뿐만 아니라 ELB 타겟 그룹과 유기적으로 연동하기 위한 Readiness Gate, GraceFul shotdown 설정이 필요합니다. (필자의 이전 블로그 글 참고)
Pod Readiness Gate
Pod Readiness Gate는 Pod가 ALB 또는 NLB의 대상 그룹(Target Group)에 완전히 등록되고, 헬스 체크에서 "Healthy" 상태로 설정될 때까지 트래픽을 받지 않도록 하는 옵션입니다. (단, IP모드에서만 동작)
해당 옵션을 사용하면 AWS Load Balancer Controller가 Pod의 readiness 상태를 관리하여, 해당 Pod가 ALB/NLB에서 "Healthy" 상태가 될 때까지 기존 Pod를 종료하지 않고 트래픽을 보내지 않습니다.
(로드밸런서 V2 기준 이상)
설정 하는 방법은 네임스페이스에 아래 라벨을 추가하고 네임스페이스 파드들을 삭제하여 재배포시켜줍니다.
kubectl label namespace default elbv2.k8s.aws/pod-readiness-gate-inject=enabled
kubectl delete pod --all적용 후 파드를 확인하면 Readiness Gate 옵션이 추가됨을 확인할 수 있습니다.
kubectl describe pod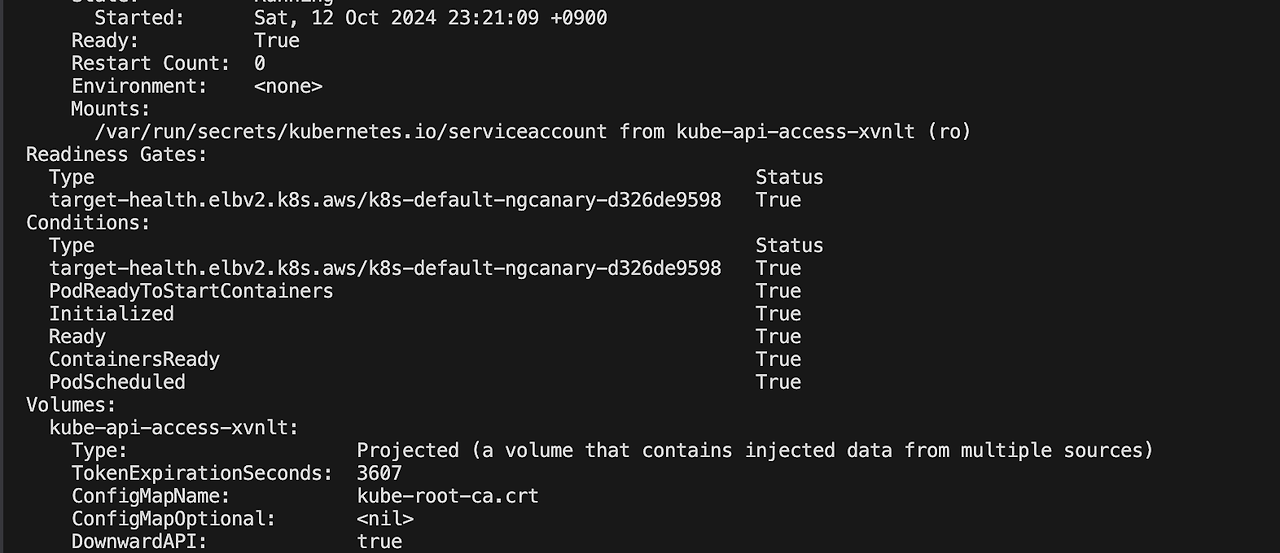
이후 Ingress annotation 에 healthcheck-path를 지정합니다.
kind: Ingress
metadata:
name: django-ingress
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/healthcheck-path: /logistics/health # URL 설정
alb.ingress.kubernetes.io/success-codes: '200-301'
alb.ingress.kubernetes.io/healthcheck-interval-seconds: '3'- ALB health 경로를 Prestop 명령어에서 설정하는 URL로 설정합니다. 만약 preStop 후크가 실행되면 해당 파드를 비정상으로 간주하여 더 이상 트래픽을 전달하지 않습니다.
Pod GraceFul Shotdown with ALB
파드 GraceFul Shotdown 를 통해 파드 축소 과정 동안 사용자에게 중단이 없도록 설정할 수 있습니다.
설정은 파드 내 PreStop, readinessProbe를 설정한 URL을 ALB annotation health check로 지정합니다.
PreStop 후크는 포드가 중지되기 전에 SIGTERM 신호를 받으면, 준비 상태를 비정상으로 표시하여 더 이상 트래픽을 받지 않도록 설정합니다.
비정상인 대상 그룹을 확인한 로드 밸런서는 해당 포드를 대상으로 트래픽을 보내지 않게 되어, 트래픽 손실을 방지합니다.
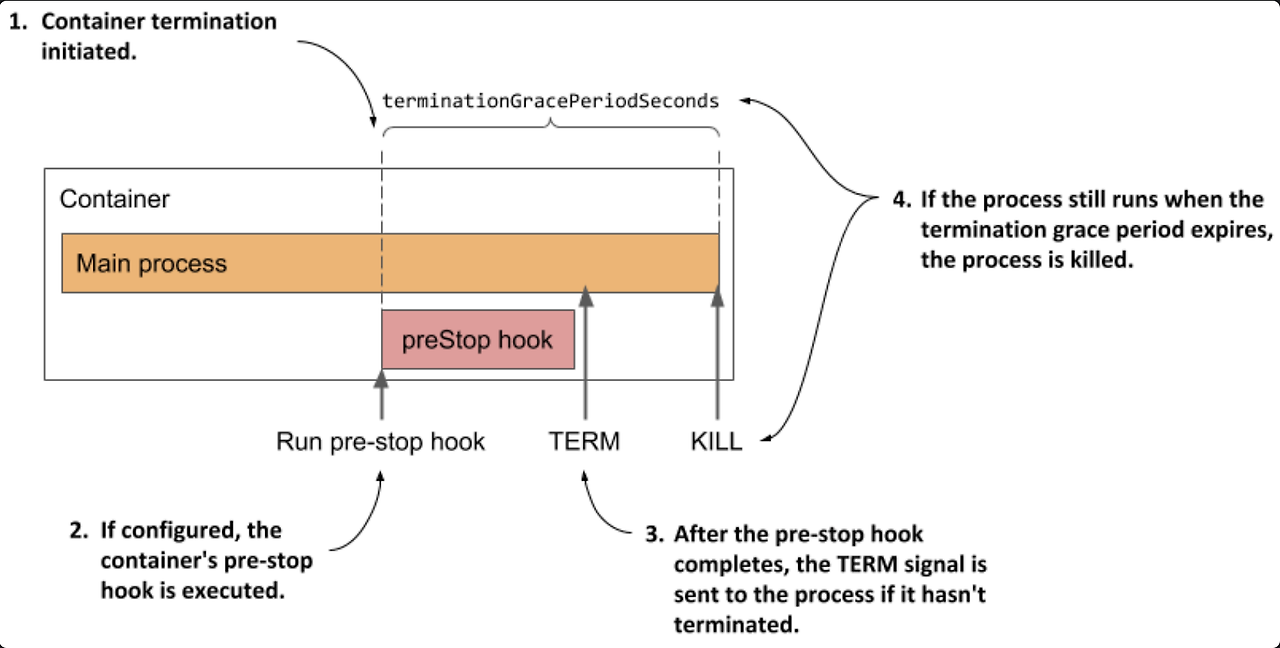
AWS 블로그에서 활용한 예제를 통해 옵션 설정 값을 확인하겠습니다.
preStop:
exec:
command: ["/bin/sh", "-c", "sed -i 's/health/nothealthy/g' /usr/src/app/logistics/health.py && sleep 120"]- 파드가 종료하기 전 prestop 으로 설정된 명령어를 실행합니다. 명령어에서는 logistics/health 파일에서 health라는 문자열을 nothealthy 로 설정하여 로드밸런서가 비정상으로 체크되어 더이상 트래픽을 주지않도록 설정합니다.
readinessProbe:
httpGet:
path: /logistics/health
port: 8000
initialDelaySeconds: 3
periodSeconds: 3- 파드 시작 3초 후 3초 동안 해당 URL 를 호출하여 파드 정상 상태를 확인합니다. 해당 URL이 호출되지 않으면 파드를 죽이며 죽이기 전 위 prestop 명령어가 실행됩니다.
구성 환경 배포
필자는 이전 블로그 글에서 사용한 테라폼 EKS 모듈을 사용하였습니다.
아래 환경 구성시 EKS version 1.29, m.large 서버 2대로 EKS 클러스터로 구성됩니다.
git clone https://github.com/aws-samples/cilium-service-mesh-on-eks.git
cd cilium-mesh-on-eks/terraform
terraform init
terraform apply --auto-approve - 배포에 약 15분정도 소요됩니다.

- AWS 로드밸런서 컨트롤러는 테라폼 EKS blueprint 모듈로 인해 설치됩니다.
예제 애플리케이션 배포
2048 애플리케이션에 위 Downtime Zero 설정을 하여 롤링업데이트를 테스트하겠습니다.
cat << EOT > ingress.yaml
apiVersion: v1
kind: Namespace
metadata:
name: game-2048
labels:
elbv2.k8s.aws/pod-readiness-gate-inject: enabled
---
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: game-2048
name: deployment-2048
spec:
selector:
matchLabels:
app.kubernetes.io/name: app-2048
replicas: 2
template:
metadata:
labels:
app.kubernetes.io/name: app-2048
spec:
terminationGracePeriodSeconds: 70
containers:
- image: alexwhen/docker-2048
imagePullPolicy: Always
name: "2048"
ports:
- containerPort: 80
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 40"]
---
apiVersion: v1
kind: Service
metadata:
namespace: game-2048
name: service-2048
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
type: NodePort
selector:
app.kubernetes.io/name: app-2048
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: game-2048
name: ingress-2048
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
spec:
ingressClassName: alb
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: service-2048
port:
number: 80
EOT
kubectl apply -f ingress.yaml
kubectl get ingress -A
kubectl describe ingress ingress-2048 -n game-2048 - 위 네임스페이스에 pod-readiness-gate-inject 옵션을 설정합니다.
- deployment 에 Prestop 과 terminationGracePeriodSeconds 를 설정합니다.
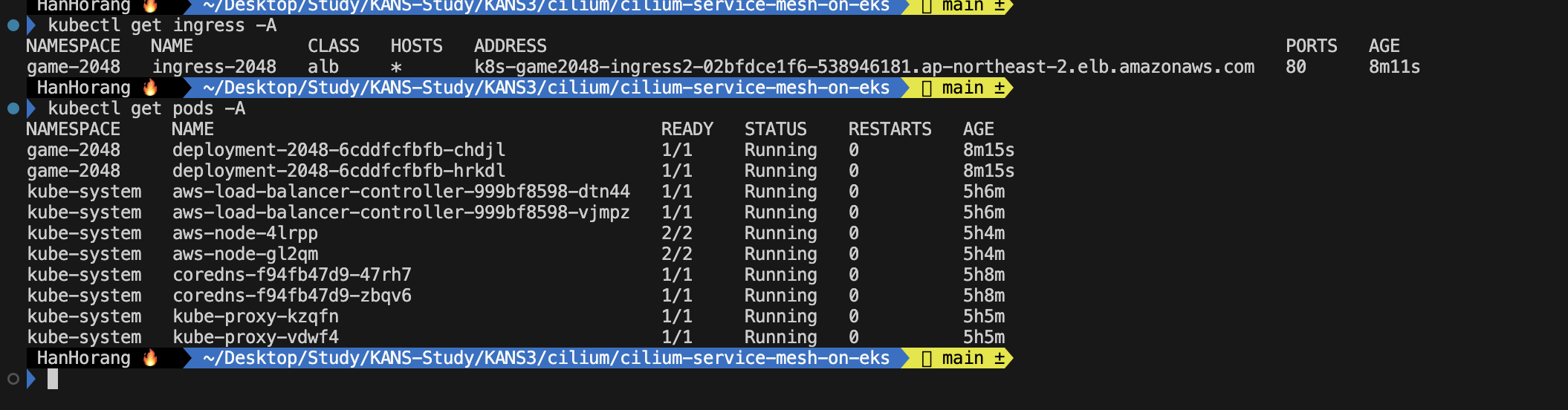
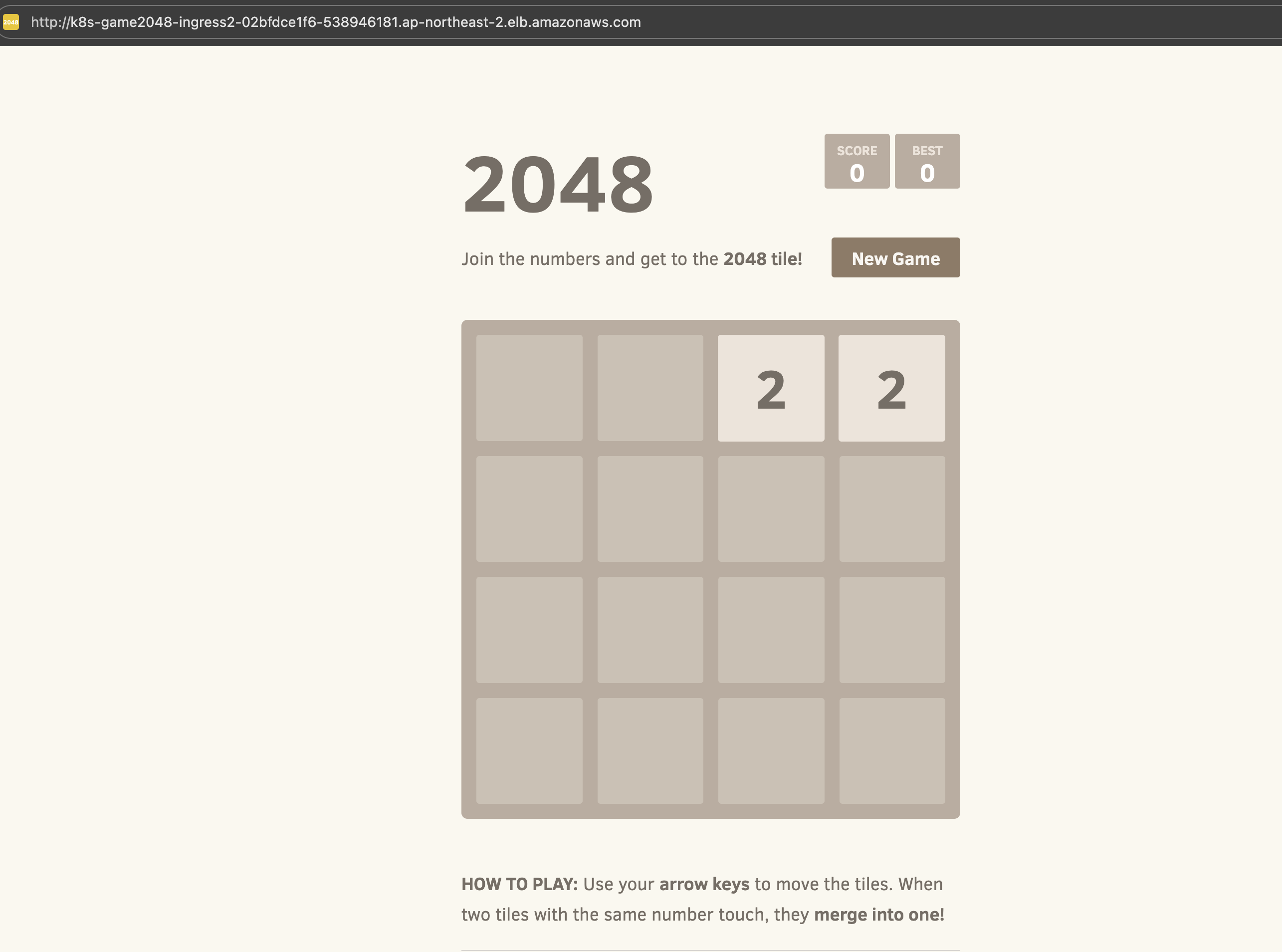
롤링 업데이트를 하기 전 과부하 테스트를 위해 Locust 를 배포하겠습니다.
# repo 설치
helm repo add deliveryhero https://charts.deliveryhero.io/
helm repo update
helm repo list
cat < locustfile.py && cat locustfile.py
from locust import HttpUser, task, between
class UserBehavior(HttpUser):
wait_time = between(1, 2.5)
@task
def get_home_page(self):
self.client.get("http://k8s-game2048-ingress2-02bfdce1f6-538946181.ap-northeast-2.elb.amazonaws.com/")
EOF
# 스크립트 배포
kubectl create configmap eks-loadtest-locustfile --from-file ./locustfile.py
# locust 배포
helm upgrade --install locust deliveryhero/locust \
--set loadtest.name=eks-loadtest \
--set loadtest.locust_locustfile_configmap=eks-loadtest-locustfile \
--set loadtest.locust_locustfile=locustfile.py \
--set worker.hpa.enabled=true \
--set worker.hpa.minReplicas=5
kubectl --namespace default port-forward service/locust 8089:8089
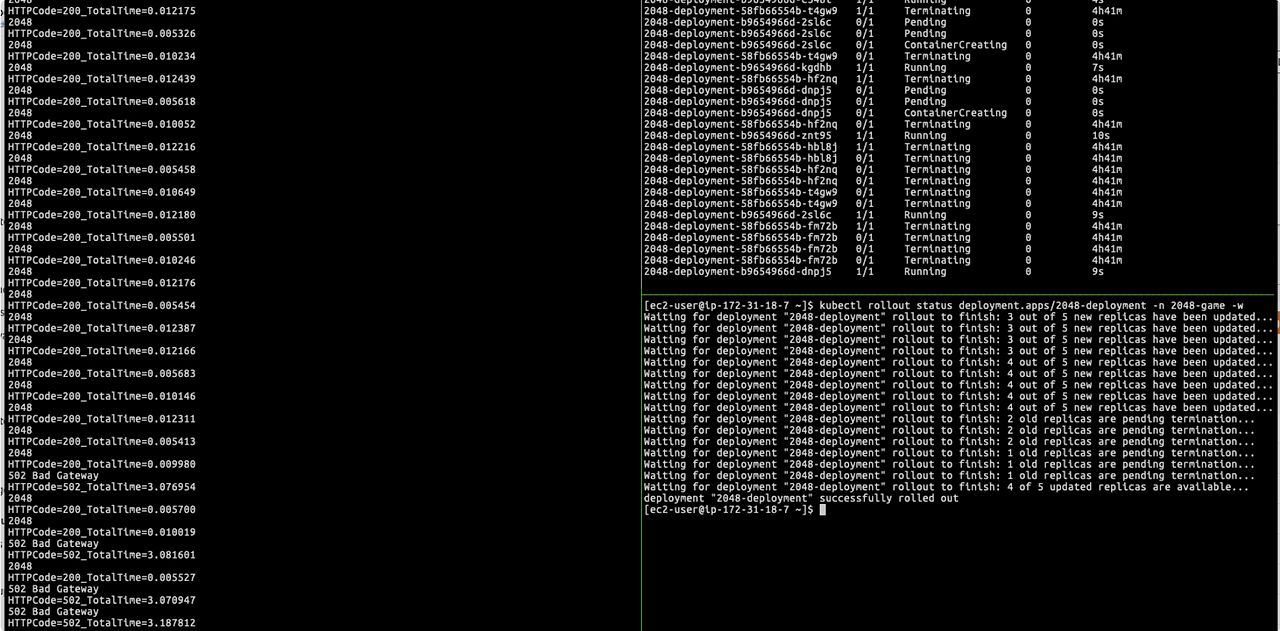
설정이 끝났다면 파드 재시작을 통해 ELB 5XX 결과를 확인하겠습니다.
kubectl rollout restart deployment my-deployment -n 2048-game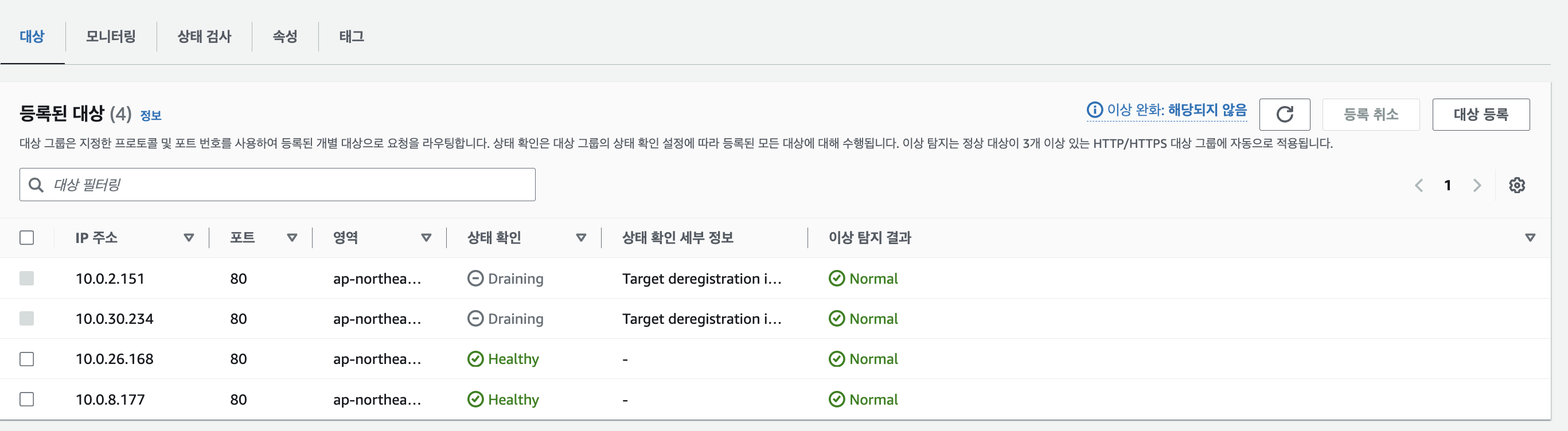
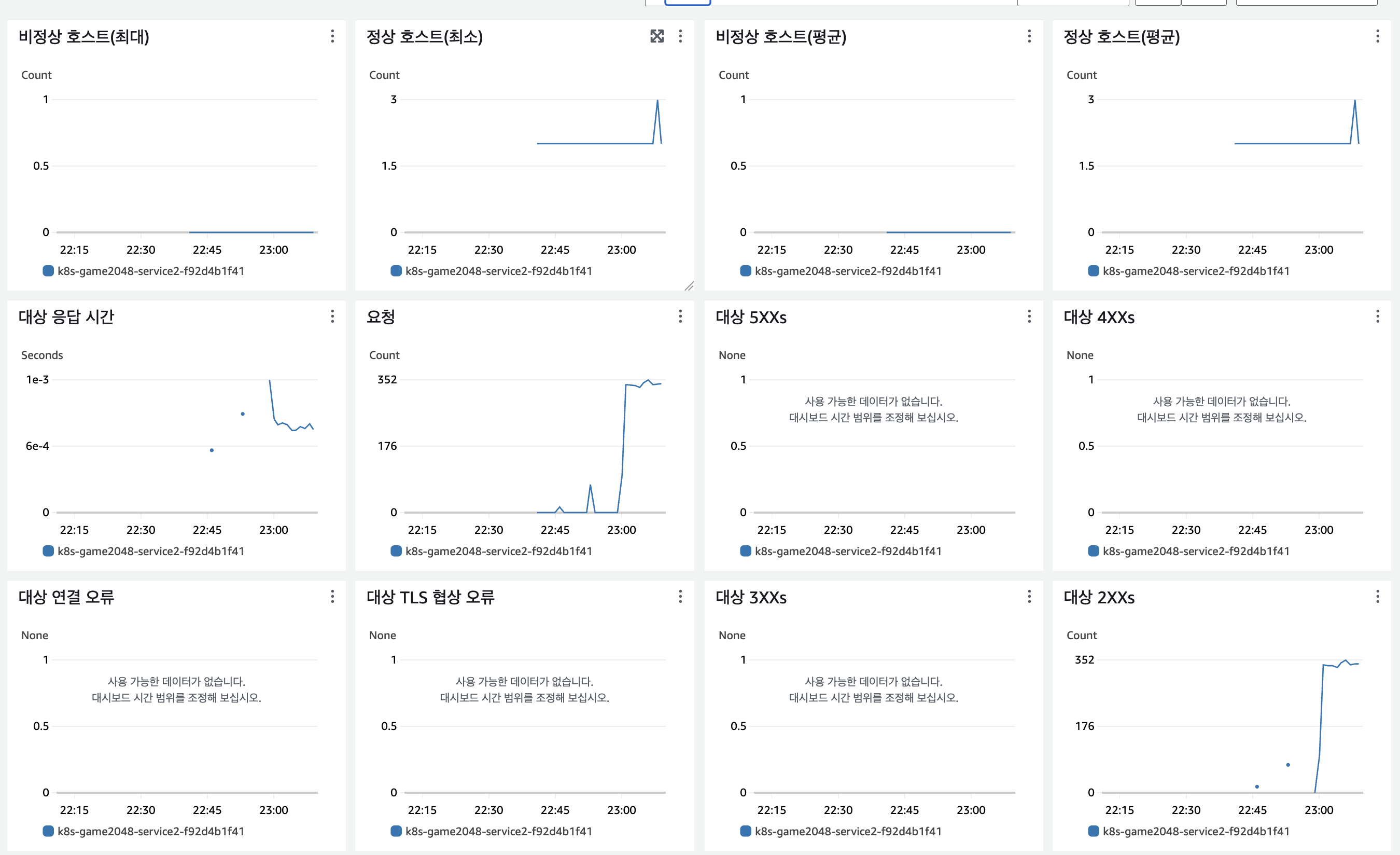
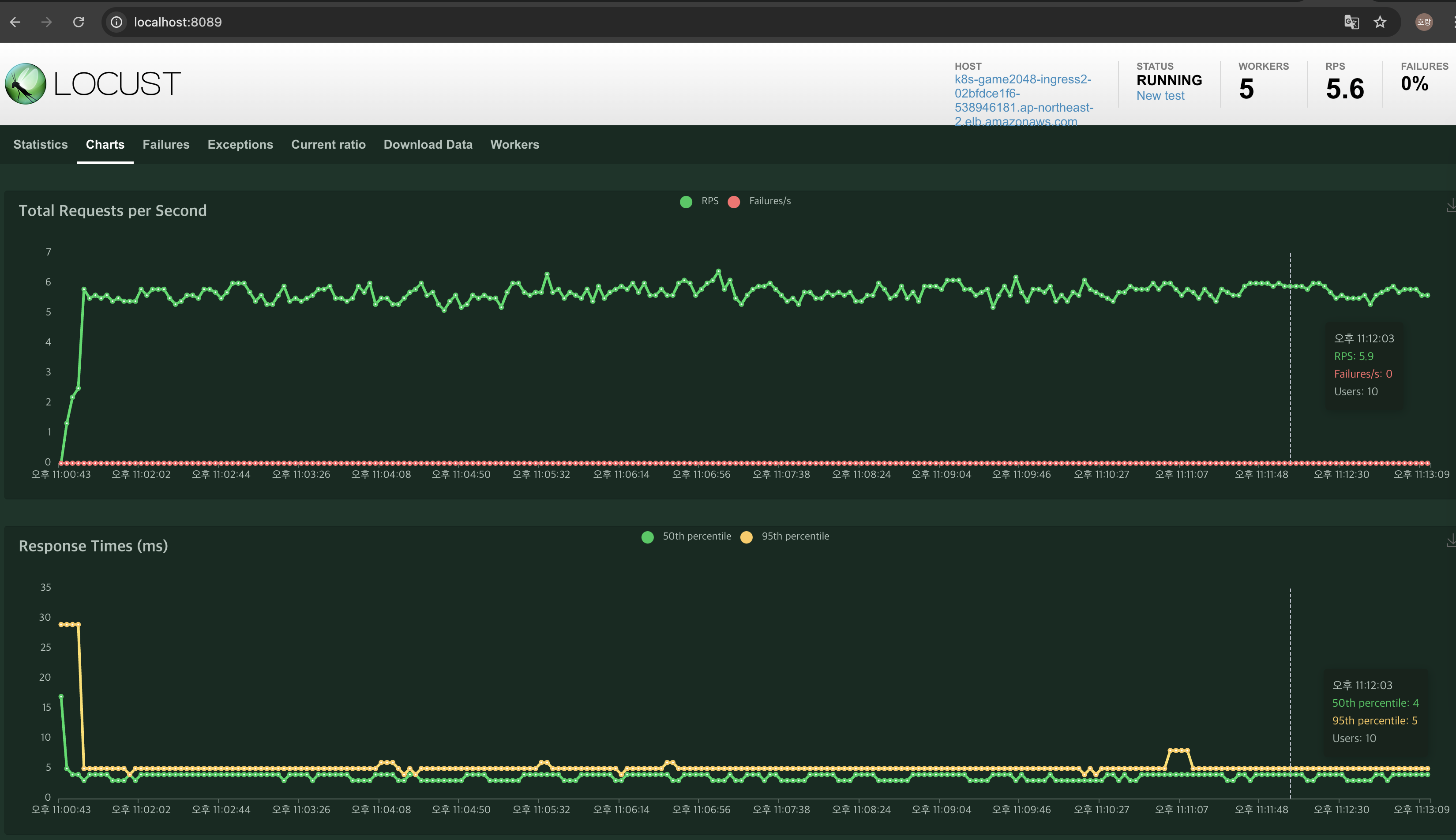
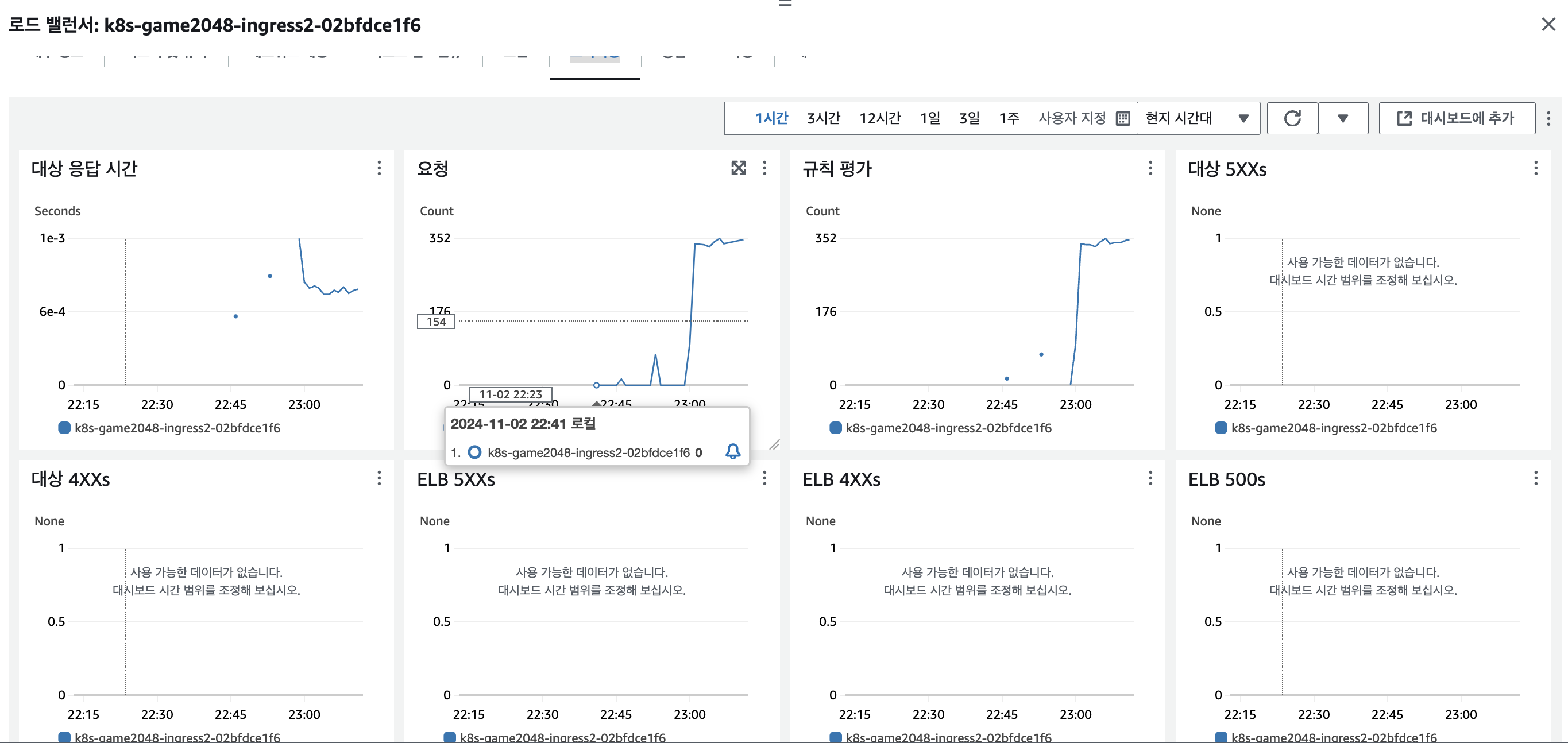
User 10, request 1 기준 테스트로 5XX 에러는 없었으며, 재기동 시간동안 지연시간만 미세하게 발생한 것으로 확인했습니다.
리소스 제거
terraform destroy -auto-approve쿠버네티스의 창시자 중 한 명인 Joe Beda는 "쿠버네티스 파드는 언제든지 재시작될 수 있어야 한다"고 말했습니다. 쿠버네티스는 확장성과 복원성을 갖춘 시스템으로, 인프라 수준의 안정성을 자동으로 제공하지만, 서비스 레벨에서 무중단 운영을 보장하려면 추가 설정이 필요합니다.
이번 글에서는 추가 설정인 readiness gate, graceful shotdown 설정과 테스트를 위해 실제 무중단을 확인하였습니다.
참고
https://hanhorang31.github.io/post/locust-test/
'Cloud' 카테고리의 다른 글
| Github Action CI/CD (1) | 2024.12.15 |
|---|---|
| 도커 기반 애플리케이션 CI/CD 구성 (0) | 2024.12.08 |
| Cilium Service Mesh on EKS (1) | 2024.10.26 |
| EKS VPC CNI 네트워크 최적화 설정과 Kubeflow에서의 istio 구성 (2) | 2024.10.20 |
| AWS Load Balancer Controller 기능 분석 (4) | 2024.10.13 |